JIT Design and Implementation
هذا المستند يشرح تصميم وتنفيذ JIT الخاص بـ Julia، بعد أن تنتهي عملية توليد الشيفرة ويُنتج IR غير المحسن لـ LLVM. JIT مسؤول عن تحسين وتجميع هذا IR إلى شيفرة آلة، وعن ربطها في العملية الحالية وجعل الشيفرة متاحة للتنفيذ.
Introduction
JIT مسؤول عن إدارة موارد التجميع، والبحث عن الشيفرة المجمعة مسبقًا، وتجميع الشيفرة الجديدة. إنه مبني أساسًا على تقنية LLVM On-Request-Compilation (ORCv2)، التي توفر دعمًا لعدد من الميزات المفيدة مثل التجميع المتزامن، والتجميع الكسول، والقدرة على تجميع الشيفرة في عملية منفصلة. على الرغم من أن LLVM يوفر مجمع JIT أساسي في شكل LLJIT، إلا أن جوليا تستخدم العديد من واجهات برمجة التطبيقات ORCv2 مباشرة لإنشاء مجمع JIT مخصص خاص بها.
Overview
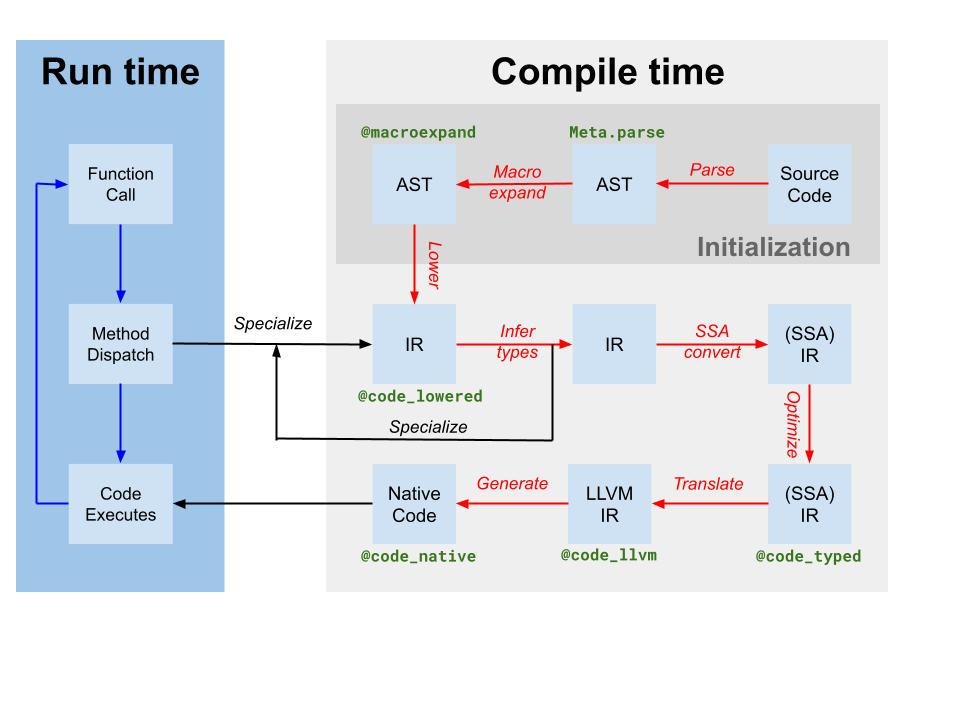
يولد Codegen وحدة LLVM تحتوي على IR لوظائف جوليا واحدة أو أكثر من IR SSA جوليا الأصلية التي تم إنتاجها بواسطة استنتاج النوع (المعلمة كترجمة في مخطط المترجم أعلاه). كما أنه ينتج خريطة من مثيل الشيفرة إلى اسم وظيفة LLVM. ومع ذلك، على الرغم من أنه تم تطبيق بعض التحسينات بواسطة المترجم القائم على جوليا على IR جوليا، لا يزال IR LLVM المنتج بواسطة Codegen يحتوي على العديد من الفرص للتحسين. وبالتالي، فإن الخطوة الأولى التي يتخذها JIT هي تشغيل خط أنابيب تحسين مستقل عن الهدف[tdp] على وحدة LLVM. ثم، يقوم JIT بتشغيل خط أنابيب تحسين يعتمد على الهدف، والذي يتضمن تحسينات محددة للهدف وتوليد الشيفرة، ويخرج ملف كائن. أخيرًا، يقوم JIT بربط ملف الكائن الناتج في العملية الحالية ويجعل الشيفرة متاحة للتنفيذ. كل هذا يتم التحكم فيه بواسطة الشيفرة في src/jitlayers.cpp.
حاليًا، يُسمح بدخول خيط واحد فقط في كل مرة إلى خط أنابيب تحسين-تجميع-ربط، بسبب القيود المفروضة من قبل أحد روابطنا (RuntimeDyld). ومع ذلك، تم تصميم JIT لدعم التحسين والتجميع المتزامن، ومن المتوقع أن يتم رفع قيود الرابط في المستقبل عندما يتم استبدال RuntimeDyld بالكامل على جميع المنصات.
Optimization Pipeline
تستند عملية التحسين إلى مدير المرور الجديد لـ LLVM، ولكن تم تخصيص العملية لاحتياجات جوليا. يتم تعريف العملية في src/pipeline.cpp، وتتم بشكل عام من خلال عدد من المراحل كما هو موضح أدناه.
تبسيط مبكر
- تستخدم هذه التمريرات بشكل أساسي لتبسيط IR وتوحيد الأنماط بحيث يمكن للتمريرات اللاحقة التعرف على تلك الأنماط بسهولة أكبر. بالإضافة إلى ذلك، يتم تقليل مكالمات الدوال الداخلية المختلفة مثل تلميحات توقع الفرع والتعليقات إلى بيانات وصفية أخرى أو ميزات IR أخرى.
SimplifyCFG(تبسيط رسم بياني تدفق التحكم)،DCE(إزالة الشيفرة الميتة)، وSROA(استبدال المتجهات المجمعة) هي بعض من اللاعبين الرئيسيين هنا.
- تستخدم هذه التمريرات بشكل أساسي لتبسيط IR وتوحيد الأنماط بحيث يمكن للتمريرات اللاحقة التعرف على تلك الأنماط بسهولة أكبر. بالإضافة إلى ذلك، يتم تقليل مكالمات الدوال الداخلية المختلفة مثل تلميحات توقع الفرع والتعليقات إلى بيانات وصفية أخرى أو ميزات IR أخرى.
تحسين مبكر
- تكون هذه التمريرات عادةً رخيصة وتركز بشكل أساسي على تقليل عدد التعليمات في IR ونشر المعرفة إلى تعليمات أخرى. على سبيل المثال،
EarlyCSEتُستخدم لتنفيذ حذف التعبيرات الفرعية الشائعة، وInstCombineوInstSimplifyتقوم بعدد من تحسينات الفتح الصغيرة لجعل العمليات أقل تكلفة.
- تكون هذه التمريرات عادةً رخيصة وتركز بشكل أساسي على تقليل عدد التعليمات في IR ونشر المعرفة إلى تعليمات أخرى. على سبيل المثال،
تحسين الحلقات
- تقوم هذه التمريرات بتوحيد وتبسيط الحلقات. الحلقات غالبًا ما تكون كودًا ساخنًا، مما يجعل تحسين الحلقات مهمًا للغاية للأداء. تشمل اللاعبين الرئيسيين هنا
LoopRotate،LICM، وLoopFullUnroll. يحدث أيضًا بعض إلغاء فحص الحدود هنا، نتيجة لتمريرIRCEالذي يمكن أن يثبت أن بعض الحدود لا تتجاوز أبدًا.
- تقوم هذه التمريرات بتوحيد وتبسيط الحلقات. الحلقات غالبًا ما تكون كودًا ساخنًا، مما يجعل تحسين الحلقات مهمًا للغاية للأداء. تشمل اللاعبين الرئيسيين هنا
تحسين المتجهات
- تحتوي سلسلة تحسين المتجهات على عدد من المراحل الأكثر تكلفة، ولكنها أكثر قوة مثل
GVN(تعداد القيمة العالمية)،SCCP(نشر الشرط الثابت النادر)، وجولة أخرى من القضاء على فحص الحدود. هذه المراحل مكلفة، لكنها يمكن أن تزيل غالبًا كميات كبيرة من الشيفرة وتجعل التوجيه أكثر نجاحًا وفعالية. تتخلل عدة مراحل أخرى من التبسيط والتحسين المراحل الأكثر تكلفة لتقليل كمية العمل التي يتعين عليهم القيام به.
- تحتوي سلسلة تحسين المتجهات على عدد من المراحل الأكثر تكلفة، ولكنها أكثر قوة مثل
توجيه المتجهات
- Automatic vectorization هو تحويل قوي للغاية لشفرة كثيفة الاستخدام لوحدة المعالجة المركزية. باختصار، يسمح التوجيه بتنفيذ single instruction on multiple data (SIMD)، على سبيل المثال، إجراء 8 عمليات جمع في نفس الوقت. ومع ذلك، فإن إثبات أن الشفرة قادرة على التوجيه ومربحة للتوجيه أمر صعب، وهذا يعتمد بشكل كبير على عمليات التحسين السابقة لتعديل IR إلى حالة تجعل التوجيه يستحق ذلك.
الخفض الجوهري
- تقوم جوليا بإدراج عدد من الدوال الداخلية المخصصة، لأسباب مثل تخصيص الكائنات، وجمع القمامة، ومعالجة الاستثناءات. تم وضع هذه الدوال الداخلية في الأصل لجعل فرص التحسين أكثر وضوحًا، لكنها الآن تُخفض إلى LLVM IR لتمكين إصدار IR ككود آلة.
تنظيف
- تعتبر هذه التمريرات تحسينات في الفرصة الأخيرة، وتقوم بإجراء تحسينات صغيرة مثل تمرير الضرب-الجمع المدمج وتبسيط القسمة-الباقي. بالإضافة إلى ذلك، فإن الأهداف التي لا تدعم أرقام النقطة العائمة بدقة نصف ستقوم بتخفيض تعليماتها بدقة نصف إلى تعليمات بدقة مفردة هنا، وتضاف تمريرات لتوفير دعم المراقب.
Target-Dependent Optimization and Code Generation
يوفر LLVM تحسينات تعتمد على الهدف وتوليد كود الآلة في نفس خط الأنابيب، الموجود في TargetMachine لمنصة معينة. تشمل هذه المراحل اختيار التعليمات، جدولة التعليمات، تخصيص السجلات، وإصدار كود الآلة. توفر وثائق LLVM نظرة عامة جيدة على العملية، ويعتبر كود مصدر LLVM أفضل مكان للبحث عن تفاصيل خط الأنابيب والمراحل.
Linking
حاليًا، تنتقل جوليا بين رابطين: رابط RuntimeDyld الأقدم، ورابط JITLink الأحدث. يحتوي JITLink على عدد من الميزات التي لا يمتلكها RuntimeDyld، مثل الربط المتزامن والقابل لإعادة الدخول، ولكنه يفتقر حاليًا إلى دعم جيد لتكاملات التوصيف ولا يدعم بعد جميع المنصات التي يدعمها RuntimeDyld. مع مرور الوقت، من المتوقع أن يحل JITLink محل RuntimeDyld تمامًا. يمكن العثور على مزيد من التفاصيل حول JITLink في وثائق LLVM.
Execution
بمجرد ربط الشيفرة في العملية الحالية، تصبح متاحة للتنفيذ. يتم إبلاغ الشيفرة المولدة بذلك من خلال تحديث حقول invoke و specsigflags و specptr بشكل مناسب. تدعم الشيفرات المحدثة ترقية حقول invoke و specsigflags و specptr، طالما أن كل مجموعة من هذه الحقول الموجودة في أي لحظة زمنية معينة صالحة للاستدعاء. وهذا يسمح لـ JIT بتحديث هذه الحقول دون إبطال الشيفرات المحدثة الموجودة، مما يدعم JIT متزامن محتمل في المستقبل. على وجه التحديد، قد تكون الحالات التالية صالحة:
invokeهو NULL،specsigflagsهو 0b00،specptrهو NULL- هذه هي الحالة الأولية لـ codeinst، وتشير إلى أن codeinst لم يتم تجميعه بعد.
invokeغير فارغ،specsigflagsهو 0b00،specptrهو NULL- هذا يشير إلى أن
codeinstلم يتم تجميعه مع أي تخصيص، وأنه يجب استدعاءcodeinstمباشرة. لاحظ أنه في هذه الحالة، لا تقرأinvokeأيًا من حقولspecsigflagsأوspecptr، وبالتالي يمكن تعديلها دون إبطال مؤشرinvoke.
- هذا يشير إلى أن
invokeغير فارغ،specsigflagsهو 0b10،specptrغير فارغ- هذا يشير إلى أن الكود تم تجميعه، ولكن تم اعتبار أن توقيع الدالة المتخصصة غير ضروري من قبل توليد الكود.
invokeغير فارغ،specsigflagsهو 0b11،specptrغير فارغ- هذا يشير إلى أن الكود تم تجميعه، وأن توقيع دالة متخصص كان ضروريًا من قبل توليد الكود. يحتوي حقل
specptrعلى مؤشر لتوقيع الدالة المتخصص. يُسمح لمؤشرinvokeبقراءة كل من حقليspecsigflagsوspecptr.
- هذا يشير إلى أن الكود تم تجميعه، وأن توقيع دالة متخصص كان ضروريًا من قبل توليد الكود. يحتوي حقل
بالإضافة إلى ذلك، هناك عدد من الحالات الانتقالية المختلفة التي تحدث خلال عملية التحديث. لأخذ هذه الحالات المحتملة في الاعتبار، يجب استخدام أنماط الكتابة والقراءة التالية عند التعامل مع هذه الحقول الخاصة بـ codeinst.
عند كتابة
invokeوspecsigflagsوspecptr:- قم بتنفيذ عملية مقارنة-تبادل ذرية لـ
specptrبافتراض أن القيمة القديمة كانت NULL. يجب أن تحتوي هذه العملية على ترتيب على الأقل من نوع الاستحواذ-الإفراج، لتوفير ضمانات ترتيب العمليات في الذاكرة المتبقية في الكتابة. - إذا كان
specptrغير فارغ، توقف عن عملية الكتابة وانتظر حتى يتم كتابة البت 0b10 منspecsigflags. - اكتب البت المنخفض الجديد لـ
specsigflagsإلى قيمته النهائية. قد تكون هذه كتابة مريحة. - اكتب المؤشر الجديد
invokeإلى قيمته النهائية. يجب أن يحتوي هذا على ترتيب ذاكرة للإفراج على الأقل للتزامن مع قراءاتinvoke. - قم بتعيين البت الثاني من
specsigflagsإلى 1. يجب أن يكون هذا على الأقل ترتيب ذاكرة للإصدار لمزامنة مع قراءاتspecsigflags. تكمل هذه الخطوة عملية الكتابة وتعلن لجميع الخيوط الأخرى أنه قد تم تعيين جميع الحقول.
- قم بتنفيذ عملية مقارنة-تبادل ذرية لـ
عند قراءة جميع
invokeوspecsigflagsوspecptr:- اقرأ حقل
invokeمع ترتيب ذاكرة على الأقل acquire. سيتم الإشارة إلى هذا التحميل باسمinitial_invoke. - إذا كان
initial_invokeNULL، فإنcodeinstلم يصبح قابلاً للتنفيذ بعد.invokeهو NULL، ويمكن اعتبارspecsigflagsكـ 0b00، ويمكن اعتبارspecptrكـ NULL. - اقرأ حقل
specptrبترتيب ذاكرة لا يقل عن ترتيب الاستحواذ. - إذا كان
specptrNULL، فلا يجب أن يعتمد مؤشرinitial_invokeعلىspecptrلضمان التنفيذ الصحيح. لذلك، فإنinvokeغير NULL، ويمكن اعتبارspecsigflagsكـ 0b00، ويمكن اعتبارspecptrكـ NULL. - إذا كان
specptrغير فارغ، فقد لا يكونinitial_invokeهو الحقل النهائيinvokeالذي يستخدمspecptr. يمكن أن يحدث هذا إذا تم كتابةspecptr، ولكن لم يتم كتابةinvokeبعد. لذلك، يجب الدوران على البت الثاني منspecsigflagsحتى يتم تعيينه إلى 1 مع ترتيب ذاكرة على الأقل من نوع acquire. - إعادة قراءة حقل
invokeبترتيب ذاكرة على الأقل acquire. سيتم الإشارة إلى هذا التحميل باسمfinal_invoke. - اقرأ حقل
specsigflagsبأي ترتيب للذاكرة. invokeهوfinal_invoke،specsigflagsهو القيمة المقروءة في الخطوة 7، وspecptrهو القيمة المقروءة في الخطوة 3.
- اقرأ حقل
عند تحديث
specptrإلى مؤشر دالة مختلف ولكنه مكافئ:- قم بإجراء تخزين إصدار لمؤشر الدالة الجديد إلى
specptr. يجب أن تكون السباقات هنا غير ضارة، حيث يجب أن يظل مؤشر الدالة القديم صالحًا، كما يجب أن تكون أي مؤشرات جديدة أيضًا صالحة. بمجرد كتابة مؤشر إلىspecptr، يجب أن يكون قابلاً للاستدعاء دائمًا سواء تم الكتابة عليه لاحقًا أم لا.
- قم بإجراء تخزين إصدار لمؤشر الدالة الجديد إلى
على الرغم من أن خطوات الكتابة والقراءة والتحديث هذه معقدة، إلا أنها تضمن أن JIT يمكنه تحديث codeinsts دون إبطال codeinsts الموجودة، وأن JIT يمكنه تحديث codeinsts دون إبطال مؤشرات invoke الموجودة. وهذا يسمح لـ JIT بإعادة تحسين الوظائف على مستويات تحسين أعلى في المستقبل، كما سيسمح أيضًا لـ JIT بدعم التجميع المتزامن للوظائف في المستقبل.
- tdpThis is not a totally-target independent pipeline, as transformations such as vectorization rely upon target information such as vector register width and cost modeling. Additionally, codegen itself makes a few target-dependent assumptions, and the optimization pipeline will take advantage of that knowledge.