JIT Design and Implementation
Este documento explica el diseño e implementación del JIT de Julia, después de que la generación de código ha finalizado y se ha producido IR de LLVM no optimizado. El JIT es responsable de optimizar y compilar este IR a código de máquina, y de enlazarlo en el proceso actual y hacer que el código esté disponible para su ejecución.
Introduction
El JIT es responsable de gestionar los recursos de compilación, buscar código previamente compilado y compilar nuevo código. Está construido principalmente sobre la tecnología On-Request-Compilation (ORCv2) de LLVM, que proporciona soporte para una serie de características útiles, como la compilación concurrente, la compilación perezosa y la capacidad de compilar código en un proceso separado. Aunque LLVM proporciona un compilador JIT básico en forma de LLJIT, Julia utiliza muchas API de ORCv2 directamente para crear su propio compilador JIT personalizado.
Overview
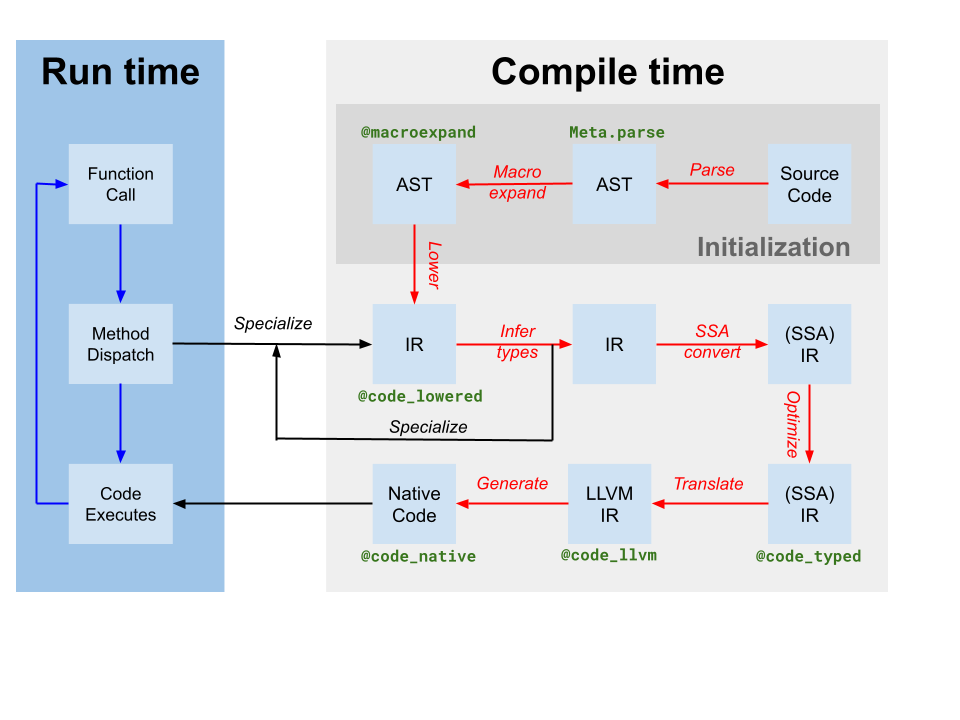
Codegen produce un módulo LLVM que contiene IR para una o más funciones de Julia a partir del IR SSA original de Julia producido por la inferencia de tipos (etiquetado como translate en el diagrama del compilador anterior). También produce un mapeo de instancia de código a nombre de función LLVM. Sin embargo, aunque se han aplicado algunas optimizaciones por el compilador basado en Julia en el IR de Julia, el IR de LLVM producido por codegen aún contiene muchas oportunidades para optimización. Así, el primer paso que toma el JIT es ejecutar una tubería de optimización independiente del objetivo[tdp] en el módulo LLVM. Luego, el JIT ejecuta una tubería de optimización dependiente del objetivo, que incluye optimizaciones específicas del objetivo y generación de código, y produce un archivo objeto. Finalmente, el JIT vincula el archivo objeto resultante en el proceso actual y hace que el código esté disponible para su ejecución. Todo esto está controlado por código en src/jitlayers.cpp.
Actualmente, solo se permite que un hilo a la vez ingrese al pipeline de optimización-compilación-enlace, debido a las restricciones impuestas por uno de nuestros enlazadores (RuntimeDyld). Sin embargo, el JIT está diseñado para soportar la optimización y compilación concurrentes, y se espera que la restricción del enlazador se levante en el futuro cuando RuntimeDyld haya sido completamente reemplazado en todas las plataformas.
Optimization Pipeline
El pipeline de optimización se basa en el nuevo administrador de pases de LLVM, pero el pipeline está personalizado para las necesidades de Julia. El pipeline se define en src/pipeline.cpp, y en términos generales avanza a través de una serie de etapas como se detalla a continuación.
Simplificación Temprana
- Estos pases se utilizan principalmente para simplificar el IR y canonizar patrones para que los pases posteriores puedan identificar esos patrones más fácilmente. Además, varias llamadas intrínsecas, como sugerencias de predicción de ramas y anotaciones, se reducen a otros metadatos u otras características del IR.
SimplifyCFG(simplificar el grafo de control de flujo),DCE(eliminación de código muerto) ySROA(reemplazo escalar de agregados) son algunos de los actores clave aquí.
- Estos pases se utilizan principalmente para simplificar el IR y canonizar patrones para que los pases posteriores puedan identificar esos patrones más fácilmente. Además, varias llamadas intrínsecas, como sugerencias de predicción de ramas y anotaciones, se reducen a otros metadatos u otras características del IR.
Optimización temprana
- Estos pases son típicamente baratos y se centran principalmente en reducir el número de instrucciones en el IR y propagar conocimiento a otras instrucciones. Por ejemplo,
EarlyCSEse utiliza para realizar la eliminación de subexpresiones comunes, yInstCombineyInstSimplifyrealizan una serie de pequeñas optimizaciones de mirilla para hacer que las operaciones sean menos costosas.
- Estos pases son típicamente baratos y se centran principalmente en reducir el número de instrucciones en el IR y propagar conocimiento a otras instrucciones. Por ejemplo,
Optimización de bucles
- Estos pases canonizan y simplifican bucles. Los bucles son a menudo código caliente, lo que hace que la optimización de bucles sea extremadamente importante para el rendimiento. Los actores clave aquí incluyen
LoopRotate,LICM, yLoopFullUnroll. También ocurre cierta eliminación de comprobaciones de límites aquí, como resultado del paseIRCEque puede demostrar que ciertos límites nunca se exceden.
- Estos pases canonizan y simplifican bucles. Los bucles son a menudo código caliente, lo que hace que la optimización de bucles sea extremadamente importante para el rendimiento. Los actores clave aquí incluyen
Optimización Escalar
- El pipeline de optimización escalar contiene una serie de pasos más costosos, pero más poderosos, como
GVN(numeración de valores globales),SCCP(propagación de constantes condicionales dispersas), y otra ronda de eliminación de comprobaciones de límites. Estos pasos son costosos, pero a menudo pueden eliminar grandes cantidades de código y hacer que la vectorización sea mucho más exitosa y efectiva. Varios otros pasos de simplificación y optimización se intercalan con los más costosos para reducir la cantidad de trabajo que tienen que hacer.
- El pipeline de optimización escalar contiene una serie de pasos más costosos, pero más poderosos, como
Vectorización
- Automatic vectorization es una transformación extremadamente poderosa para código intensivo en CPU. Brevemente, la vectorización permite la ejecución de una single instruction on multiple data (SIMD), por ejemplo, realizar 8 operaciones de suma al mismo tiempo. Sin embargo, demostrar que el código es tanto capaz de vectorización como rentable para vectorizar es difícil, y esto depende en gran medida de las pasadas de optimización previas para transformar el IR en un estado donde la vectorización valga la pena.
Bajada Intrínseca
- Julia inserta una serie de intrínsecos personalizados, por razones como la asignación de objetos, la recolección de basura y el manejo de excepciones. Estos intrínsecos se colocaron originalmente para hacer que las oportunidades de optimización fueran más obvias, pero ahora se reducen a IR de LLVM para permitir que el IR se emita como código de máquina.
Limpieza
- Estas optimizaciones de pases son de última oportunidad y realizan pequeñas optimizaciones como la propagación de multiplicación-adición fusionada y la simplificación de división-resto. Además, los objetivos que no admiten números de punto flotante de media precisión tendrán sus instrucciones de media precisión convertidas en instrucciones de precisión simple aquí, y se añaden pases para proporcionar soporte de sanitizador.
Target-Dependent Optimization and Code Generation
LLVM proporciona optimización dependiente del objetivo y generación de código máquina en el mismo pipeline, ubicado en el TargetMachine para una plataforma dada. Estos pases incluyen selección de instrucciones, programación de instrucciones, asignación de registros y emisión de código máquina. La documentación de LLVM ofrece una buena visión general del proceso, y el código fuente de LLVM es el mejor lugar para buscar detalles sobre el pipeline y los pases.
Linking
Actualmente, Julia está en transición entre dos enlazadores: el antiguo enlazador RuntimeDyld y el nuevo enlazador JITLink. JITLink contiene una serie de características que RuntimeDyld no tiene, como el enlace concurrente y reentrante, pero actualmente carece de un buen soporte para integraciones de perfilado y aún no soporta todas las plataformas que RuntimeDyld soporta. Con el tiempo, se espera que JITLink reemplace completamente a RuntimeDyld. Se pueden encontrar más detalles sobre JITLink en la documentación de LLVM.
Execution
Una vez que el código ha sido vinculado al proceso actual, está disponible para su ejecución. Este hecho se hace saber al código generador mediante la actualización de los campos invoke, specsigflags y specptr de manera apropiada. Los codeinsts admiten la actualización de los campos invoke, specsigflags y specptr, siempre que cada combinación de estos campos que exista en un momento dado sea válida para ser llamada. Esto permite que el JIT actualice estos campos sin invalidar los codeinsts existentes, apoyando un posible JIT concurrente en el futuro. Específicamente, los siguientes estados pueden ser válidos:
invokees NULL,specsigflagses 0b00,specptres NULL- Este es el estado inicial de un codeinst, e indica que el codeinst aún no ha sido compilado.
invokeno es nulo,specsigflagses 0b00,specptres NULL- Esto indica que el codeinst no fue compilado con ninguna especialización, y que el codeinst debe ser invocado directamente. Tenga en cuenta que en este caso,
invokeno lee ni los camposspecsigflagsnispecptr, y por lo tanto, pueden ser modificados sin invalidar el punteroinvoke.
- Esto indica que el codeinst no fue compilado con ninguna especialización, y que el codeinst debe ser invocado directamente. Tenga en cuenta que en este caso,
invokeno es nulo,specsigflagses 0b10,specptrno es nulo- Esto indica que el codeinst fue compilado, pero se consideró innecesaria una firma de función especializada por parte de codegen.
invokeno es nulo,specsigflagses 0b11,specptrno es nulo- Esto indica que el codeinst fue compilado y se consideró necesario un firma de función especializada por parte de codegen. El campo
specptrcontiene un puntero a la firma de función especializada. Se permite que el punteroinvokelea tanto los camposspecsigflagscomospecptr.
- Esto indica que el codeinst fue compilado y se consideró necesario un firma de función especializada por parte de codegen. El campo
Además, hay una serie de diferentes estados transitorios que ocurren durante el proceso de actualización. Para tener en cuenta estas situaciones potenciales, se deben utilizar los siguientes patrones de escritura y lectura al tratar con estos campos de codeinst.
Al escribir
invoke,specsigflagsyspecptr:- Realiza una operación de comparación e intercambio atómico de
specptrasumiendo que el valor antiguo era NULL. Esta operación de comparación e intercambio debe tener al menos un orden de adquisición-liberación, para proporcionar garantías de orden de las operaciones de memoria restantes en la escritura. - Si
specptrno era nulo, cesar la operación de escritura y esperar a que el bit 0b10 despecsigflagssea escrito. - Escribe el nuevo bit bajo de
specsigflagsa su valor final. Esto puede ser una escritura relajada. - Escribe el nuevo puntero
invokea su valor final. Esto debe tener al menos un orden de memoria de liberación para sincronizarse con las lecturas deinvoke. - Establezca el segundo bit de
specsigflagsen 1. Esto debe ser al menos un orden de memoria de liberación para sincronizarse con las lecturas despecsigflags. Este paso completa la operación de escritura y anuncia a todos los demás hilos que todos los campos han sido establecidos.
- Realiza una operación de comparación e intercambio atómico de
Al leer todos los
invoke,specsigflagsyspecptr:- Lee el campo
invokecon al menos un orden de memoria de adquisición. Esta carga se denominaráinitial_invoke. - Si
initial_invokees NULL, el codeinst aún no es ejecutable.invokees NULL,specsigflagspuede ser tratado como 0b00,specptrpuede ser tratado como NULL. - Lee el campo
specptrcon al menos un orden de memoria de adquisición. - Si
specptres NULL, entonces el punteroinitial_invokeno debe depender despecptrpara garantizar una ejecución correcta. Por lo tanto,invokees no nulo,specsigflagspuede ser tratado como 0b00,specptrpuede ser tratado como NULL. - Si
specptrno es nulo, entoncesinitial_invokepodría no ser el campo finalinvokeque utilizaspecptr. Esto puede ocurrir sispecptrha sido escrito, peroinvokeaún no ha sido escrito. Por lo tanto, gira en el segundo bit despecsigflagshasta que se establezca en 1 con al menos un orden de memoria de adquisición. - Vuelve a leer el campo
invokecon al menos un orden de memoria de adquisición. Esta carga se referirá comofinal_invoke. - Lee el campo
specsigflagscon cualquier orden de memoria. invokeesfinal_invoke,specsigflagses el valor leído en el paso 7,specptres el valor leído en el paso 3.
- Lee el campo
Al actualizar un
specptra un puntero de función diferente pero equivalente:- Realice un almacenamiento de liberación del nuevo puntero de función a
specptr. Las condiciones de carrera aquí deben ser benignas, ya que el antiguo puntero de función debe seguir siendo válido, y cualquier nuevo también debe ser válido. Una vez que se ha escrito un puntero enspecptr, debe ser siempre invocable, ya sea que se sobrescriba más tarde o no.
- Realice un almacenamiento de liberación del nuevo puntero de función a
Aunque estos pasos de escritura, lectura y actualización son complicados, garantizan que el JIT pueda actualizar codeinsts sin invalidar los codeinsts existentes, y que el JIT pueda actualizar codeinsts sin invalidar los punteros invoke existentes. Esto permite que el JIT pueda reoptimizar potencialmente funciones a niveles de optimización más altos en el futuro, y también permitirá que el JIT soporte la compilación concurrente de funciones en el futuro.
- tdpThis is not a totally-target independent pipeline, as transformations such as vectorization rely upon target information such as vector register width and cost modeling. Additionally, codegen itself makes a few target-dependent assumptions, and the optimization pipeline will take advantage of that knowledge.