JIT Design and Implementation
Bu belge, Julia'nın JIT tasarımını ve uygulamasını açıklar; kod üretimi tamamlandıktan ve optimize edilmemiş LLVM IR üretildikten sonra. JIT, bu IR'yi makine koduna optimize etmek ve derlemek, mevcut işleme bağlamak ve kodu yürütme için kullanılabilir hale getirmekle sorumludur.
Introduction
JIT, der der derleme kaynaklarını yönetmek, daha önce derlenmiş kodu aramak ve yeni kodu derlemekten sorumludur. Temelde LLVM'nin On-Request-Compilation (ORCv2) teknolojisi üzerine inşa edilmiştir ve eşzamanlı derleme, tembel derleme ve kodu ayrı bir süreçte derleme yeteneği gibi birçok yararlı özelliği destekler. LLVM, LLJIT biçiminde temel bir JIT derleyici sağlasa da, Julia kendi özel JIT derleyicisini oluşturmak için birçok ORCv2 API'sini doğrudan kullanır.
Overview
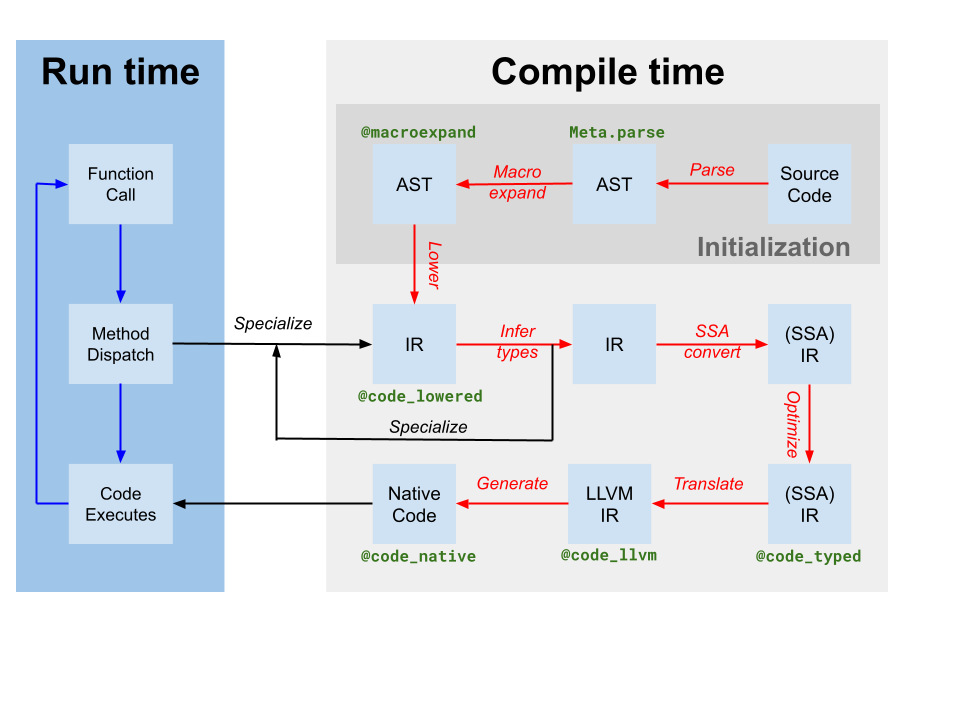
Codegen, bir veya daha fazla Julia fonksiyonu için orijinal Julia SSA IR'den (yukarıdaki derleyici diyagramında translate olarak etiketlenmiştir) IR içeren bir LLVM modülü üretir. Ayrıca, kod örneği ile LLVM fonksiyon adı arasında bir eşleme de üretir. Ancak, Julia tabanlı derleyici tarafından Julia IR üzerinde bazı optimizasyonlar uygulanmış olsa da, codegen tarafından üretilen LLVM IR hala birçok optimizasyon fırsatı içermektedir. Bu nedenle, JIT'in attığı ilk adım, LLVM modülü üzerinde hedef bağımsız bir optimizasyon hattı[tdp] çalıştırmaktır. Ardından, JIT, hedefe özgü optimizasyonlar ve kod üretimini içeren hedef bağımlı bir optimizasyon hattı çalıştırır ve bir nesne dosyası çıktısı alır. Son olarak, JIT, elde edilen nesne dosyasını mevcut işleme bağlar ve kodu yürütme için kullanılabilir hale getirir. Tüm bunlar, src/jitlayers.cpp dosyasındaki kod ile kontrol edilir.
Şu anda, yalnızca bir iş parçacığının optimize-derleme-bağlama boru hattına girmesine izin verilmektedir; bu, bağlayıcılardan biri (RuntimeDyld) tarafından getirilen kısıtlamalardan kaynaklanmaktadır. Ancak, JIT eşzamanlı optimizasyon ve derlemeyi destekleyecek şekilde tasarlanmıştır ve bağlayıcı kısıtlamasının, RuntimeDyld tüm platformlarda tamamen geçersiz kılındığında gelecekte kaldırılması beklenmektedir.
Optimization Pipeline
Optimizasyon boru hattı, LLVM'nin yeni geçiş yöneticisine dayanmaktadır, ancak boru hattı Julia'nın ihtiyaçlarına göre özelleştirilmiştir. Boru hattı src/pipeline.cpp dosyasında tanımlanmıştır ve genel olarak aşağıda detaylandırıldığı gibi bir dizi aşamadan geçmektedir.
Erken Basitleştirme
- Bu geçişler esasen IR'yi basitleştirmek ve daha sonraki geçişlerin bu desenleri daha kolay tanımlayabilmesi için kalıpları kanonikleştirmek amacıyla kullanılır. Ayrıca, dal tahmin ipuçları ve notlar gibi çeşitli içsel çağrılar, diğer meta veriler veya diğer IR özelliklerine düşürülür.
SimplifyCFG(kontrol akış grafiğini basitleştirme),DCE(ölü kod ortadan kaldırma) veSROA(agregatların skalar değiştirilmesi) burada bazı önemli oyunculardır.
- Bu geçişler esasen IR'yi basitleştirmek ve daha sonraki geçişlerin bu desenleri daha kolay tanımlayabilmesi için kalıpları kanonikleştirmek amacıyla kullanılır. Ayrıca, dal tahmin ipuçları ve notlar gibi çeşitli içsel çağrılar, diğer meta veriler veya diğer IR özelliklerine düşürülür.
Erken Optimizasyon
- Bu geçişler genellikle ucuzdur ve esasen IR'deki talimat sayısını azaltmaya ve diğer talimatlara bilgi yaymaya odaklanmıştır. Örneğin,
EarlyCSEortak alt ifade ortadan kaldırma işlemi için kullanılır veInstCombineveInstSimplifybir dizi küçük göz atma optimizasyonu gerçekleştirerek işlemleri daha az maliyetli hale getirir.
- Bu geçişler genellikle ucuzdur ve esasen IR'deki talimat sayısını azaltmaya ve diğer talimatlara bilgi yaymaya odaklanmıştır. Örneğin,
Döngü Optimizasyonu
- Bu geçişler döngüleri kanonize eder ve basitleştirir. Döngüler genellikle sıcak koddur, bu da döngü optimizasyonunu performans için son derece önemli hale getirir. Buradaki ana oyuncular şunlardır:
LoopRotate,LICM, veLoopFullUnroll. Ayrıca,IRCEgeçişinin bir sonucu olarak bazı sınır kontrolü ortadan kaldırma işlemleri de burada gerçekleşir; bu geçiş belirli sınırların asla aşılmadığını kanıtlayabilir.
- Bu geçişler döngüleri kanonize eder ve basitleştirir. Döngüler genellikle sıcak koddur, bu da döngü optimizasyonunu performans için son derece önemli hale getirir. Buradaki ana oyuncular şunlardır:
Skalar Optimizasyonu
- Skalar optimizasyon boru hattı,
GVN(küresel değer numaralandırma),SCCP(seyrek koşullu sabit yayılımı) gibi daha pahalı ama daha güçlü geçişler içerir ve başka bir sınır kontrolü kaldırma turu vardır. Bu geçişler pahalıdır, ancak genellikle büyük miktarda kodu kaldırabilir ve vektörleştirmeyi çok daha başarılı ve etkili hale getirebilir. Daha pahalı olanların arasına birkaç başka basitleştirme ve optimizasyon geçişi serpiştirilmiştir, böylece yapmaları gereken iş miktarını azaltır.
- Skalar optimizasyon boru hattı,
Vektörleştirme
- Automatic vectorization CPU yoğun kodlar için son derece güçlü bir dönüşümdür. Kısaca, vektörleştirme, bir single instruction on multiple data (SIMD) üzerinde aynı anda 8 toplama işlemi gerçekleştirilmesine olanak tanır. Ancak, kodun hem vektörleştirme yeteneğine sahip olduğunu hem de vektörleştirmenin karlı olduğunu kanıtlamak zordur ve bu, IR'yi vektörleştirmenin değerli olduğu bir duruma getirmek için önceki optimizasyon geçişlerine büyük ölçüde bağlıdır.
İçsel Düşürme
- Julia, nesne tahsisi, çöp toplama ve istisna işleme gibi nedenlerle bir dizi özel içsel işlev ekler. Bu içsel işlevler, optimizasyon fırsatlarını daha belirgin hale getirmek için başlangıçta yerleştirilmişti, ancak şimdi IR'nin makine kodu olarak yayımlanabilmesi için LLVM IR'ye indirgenmiştir.
Temizlik
- Bu geçişler son şans optimizasyonlarıdır ve çarpma-toplama yayılımı ve bölme-kalan basitleştirmesi gibi küçük optimizasyonlar gerçekleştirir. Ayrıca, yarı hassas kayan nokta sayılarını desteklemeyen hedeflerde yarı hassas talimatlar burada tek hassasiyetli talimatlara düşürülür ve sanitizasyon desteği sağlamak için geçişler eklenir.
Target-Dependent Optimization and Code Generation
LLVM, belirli bir platform için TargetMachine'de yer alan hedef bağımlı optimizasyon ve makine kodu üretimi sağlar. Bu geçişler, talep seçimi, talep zamanlaması, kayıt tahsisi ve makine kodu yayılımını içerir. LLVM belgeleri sürecin iyi bir genel görünümünü sunar ve LLVM kaynak kodu, boru hattı ve geçişler hakkında ayrıntılar için en iyi yerdir.
Linking
Şu anda, Julia iki linker arasında geçiş yapıyor: eski RuntimeDyld linker ve daha yeni JITLink linker. JITLink, RuntimeDyld'nin sahip olmadığı bir dizi özellik içeriyor, örneğin eşzamanlı ve yeniden giriş yapılabilir bağlantı, ancak şu anda profil entegrasyonları için iyi destekten yoksun ve RuntimeDyld'nin desteklediği tüm platformları henüz desteklemiyor. Zamanla, JITLink'in tamamen RuntimeDyld'nin yerini alması bekleniyor. JITLink hakkında daha fazla ayrıntı LLVM belgelerinde bulunabilir.
Execution
Kod, mevcut işleme bağlandığında, yürütme için kullanılabilir hale gelir. Bu durum, invoke, specsigflags ve specptr alanlarının uygun şekilde güncellenmesiyle üreten kodinst'e bildirilir. Kodinst'ler, mevcut her kombinasyonun geçerli olduğu sürece invoke, specsigflags ve specptr alanlarını güncellemeyi destekler. Bu, JIT'in mevcut kodinst'leri geçersiz kılmadan bu alanları güncellemesine olanak tanır ve potansiyel bir gelecekteki eşzamanlı JIT'i destekler. Özellikle, aşağıdaki durumlar geçerli olabilir:
invokeNULL'dır,specsigflags0b00'dır,specptrNULL'dır- Bu, bir codeinst'in başlangıç durumudur ve codeinst'in henüz derlenmediğini gösterir.
invokeboş değil,specsigflags0b00,specptrNULL- Bu, kodun herhangi bir özel işleme ile derlenmediğini ve kodun doğrudan çağrılması gerektiğini gösterir. Bu durumda,
invokenespecsigflagsne despecptralanlarını okumaz ve bu nedenleinvokeişaretçisini geçersiz kılmadan değiştirilebilirler.
- Bu, kodun herhangi bir özel işleme ile derlenmediğini ve kodun doğrudan çağrılması gerektiğini gösterir. Bu durumda,
invokeboş değil,specsigflags0b10,specptrboş değil- Bu, kodun derlendiğini ancak kod üretimi tarafından özel bir işlev imzasının gereksiz görüldüğünü gösterir.
invokenull değil,specsigflags0b11,specptrnull değil- Bu, kodun derlendiğini ve kod üretimi tarafından özel bir işlev imzasının gerekli görüldüğünü gösterir.
specptralanı, özel işlev imzasına bir işaretçi içerir.invokeişaretçisinin hemspecsigflagshem despecptralanlarını okumaya izin verilir.
- Bu, kodun derlendiğini ve kod üretimi tarafından özel bir işlev imzasının gerekli görüldüğünü gösterir.
Ayrıca, güncelleme süreci sırasında meydana gelen bir dizi farklı geçiş durumu vardır. Bu potansiyel durumları hesaba katmak için, bu kod alanlarıyla ilgilenirken aşağıdaki yazma ve okuma desenleri kullanılmalıdır.
invoke,specsigflags, vespecptryazarken:- NULL değerinin varsayıldığı specptr üzerinde atomik bir karşılaştırma-değiştirme işlemi gerçekleştirin. Bu karşılaştırma-değiştirme işlemi, yazmadaki kalan bellek işlemlerinin sıralama garantilerini sağlamak için en azından edinme-salım sıralamasına sahip olmalıdır.
- Eğer
specptrnull değilse, yazma işlemini durdurun vespecsigflags'ın bit 0b10'unun yazılmasını bekleyin. specsigflags'ın yeni düşük biti son değerine yazın. Bu, gevşek bir yazma olabilir.- Yeni
invokeişaretçisini nihai değerine yazın. Bu,invokeokumalarıyla senkronize olmak için en az bir serbest bellek sıralamasına sahip olmalıdır. specsigflags'ın ikinci bitini 1 olarak ayarlayın. Bu,specsigflags'ın okunmasıyla senkronize olmak için en azından bir sürüm bellek sıralaması olmalıdır. Bu adım yazma işlemini tamamlar ve diğer tüm iş parçacıklarına tüm alanların ayarlandığını bildirir.
invoke,specsigflagsvespecptr'in tamamını okurken:invokealanını en az bir edinme bellek sıralaması ile okuyun. Bu yükinitial_invokeolarak adlandırılacaktır.- Eğer
initial_invokeNULL ise, codeinst henüz çalıştırılabilir değildir.invokeNULL,specsigflags0b00 olarak değerlendirilebilir,specptrNULL olarak değerlendirilebilir. specptralanını en az bir edinme bellek sıralaması ile okuyun.- Eğer
specptrNULL ise, o zamaninitial_invokeişaretçisispecptr'a güvenerek doğru bir yürütme sağlamak zorunda değildir. Bu nedenle,invokeNULL değildir,specsigflags0b00 olarak değerlendirilebilir,specptrNULL olarak değerlendirilebilir. - Eğer
specptrnull değilse, o zamaninitial_invoke,specptr'ı kullanan soninvokealanı olmayabilir. Bu,specptryazılmışsa ancakinvokehenüz yazılmamışsa meydana gelebilir. Bu nedenle, en azından edinme bellek sıralaması ilespecsigflags'ın ikinci bitinde 1 olarak ayarlanana kadar döngüye girin. invokealanını en az bir edinme bellek sıralaması ile yeniden okuyun. Bu yükfinal_invokeolarak adlandırılacaktır.specsigflagsalanını herhangi bir bellek sıralaması ile okuyun.invokefinal_invokeolarak,specsigflags7. adımda okunan değer,specptrise 3. adımda okunan değerdir.
specptr'i farklı ama eşdeğer bir işlev işaretçisine güncellerken:- Yeni işlev işaretçisini
specptr'ye serbest bırakma deposu gerçekleştirin. Buradaki yarışlar zararsız olmalıdır, çünkü eski işlev işaretçisinin geçerli olmaya devam etmesi gerekmektedir ve yeni olanların da geçerli olması gerekmektedir. Bir işaretçispecptr'ye yazıldığında, daha sonra üzerine yazılıp yazılmadığına bakılmaksızın her zaman çağrılabilir olmalıdır.
- Yeni işlev işaretçisini
Bu yazma, okuma ve güncelleme adımları karmaşık olsa da, JIT'in mevcut codeinst'leri geçersiz kılmadan codeinst'leri güncelleyebilmesini ve JIT'in mevcut invoke işaretçilerini geçersiz kılmadan codeinst'leri güncelleyebilmesini sağlar. Bu, JIT'in gelecekte fonksiyonları daha yüksek optimizasyon seviyelerinde yeniden optimize etmesine ve ayrıca JIT'in gelecekte fonksiyonların eşzamanlı derlemesini desteklemesine olanak tanır.
- tdpThis is not a totally-target independent pipeline, as transformations such as vectorization rely upon target information such as vector register width and cost modeling. Additionally, codegen itself makes a few target-dependent assumptions, and the optimization pipeline will take advantage of that knowledge.