Garbage Collection in Julia
Introduction
Julia dispose d'un collecteur de marquage et de balayage non mobile, partiellement concurrent, parallèle, générationnel et principalement précis (une interface pour le balayage de pile conservateur est fournie en option pour les utilisateurs qui souhaitent appeler Julia depuis C).
Allocation
Julia utilise deux types d'allocateurs, la taille de la demande d'allocation déterminant lequel est utilisé. Les objets jusqu'à 2 Ko sont alloués sur un allocateur de pool de liste libre par thread, tandis que les objets de plus de 2 Ko sont alloués via libc malloc.
L'allocateur de pool de Julia partitionne les objets en différentes classes de taille, de sorte qu'une page mémoire gérée par l'allocateur de pool (qui s'étend sur 4 pages du système d'exploitation sur des plateformes 64 bits) ne contient que des objets de la même classe de taille. Chaque page mémoire de l'allocateur de pool est associée à des métadonnées de page stockées sur des listes sans verrou par thread. Les métadonnées de la page contiennent des informations telles que si la page a des objets vivants, le nombre de slots libres et les décalages vers le premier et le dernier objet dans la liste des libres contenue dans cette page. Ces métadonnées sont utilisées pour optimiser la phase de collecte : une page qui n'a pas d'objets vivants peut être renvoyée au système d'exploitation sans avoir besoin de la scanner, par exemple.
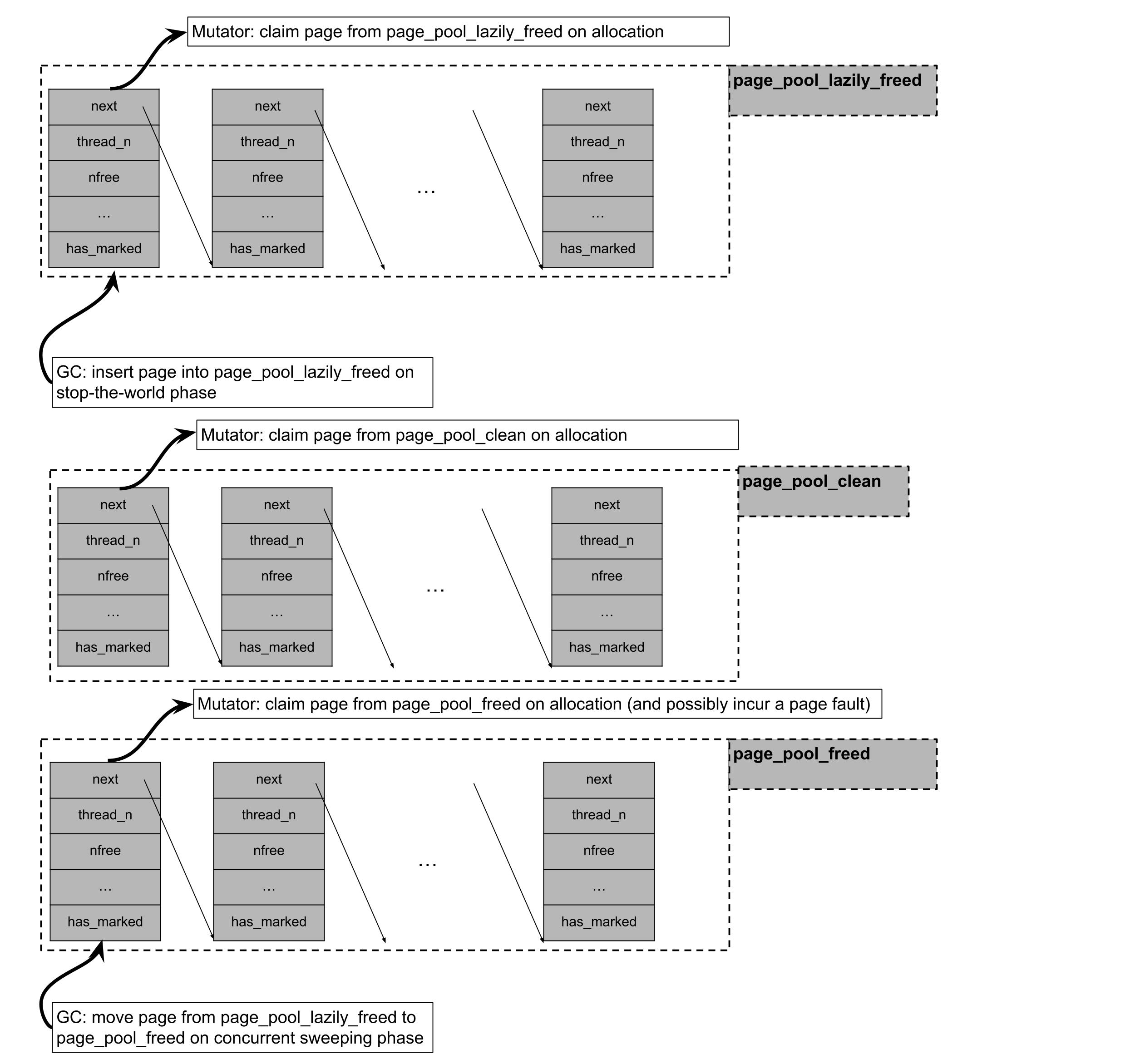
Bien qu'une page qui n'ait aucun objet puisse être renvoyée au système d'exploitation, ses métadonnées associées sont allouées de manière permanente et peuvent survivre à la page donnée. Comme mentionné ci-dessus, les métadonnées pour les pages allouées sont stockées dans des listes sans verrou par thread. Les métadonnées pour les pages libres, cependant, peuvent être stockées dans trois listes sans verrou distinctes en fonction de si la page a été mappée mais jamais accédée (page_pool_clean), ou si la page a été balayée paresseusement et attend d'être conseillée par un thread GC en arrière-plan (page_pool_lazily_freed), ou si la page a été conseillée (page_pool_freed).
L'allocateur de pool de Julia suit une discipline d'allocation "par niveaux". Lorsqu'il demande une page mémoire pour l'allocateur de pool, Julia :
Essayez de réclamer une page de
page_pool_lazily_freed, qui contient des pages qui étaient vides lors de la dernière phase d'arrêt du monde, mais qui n'ont pas encore été madivisées par un thread de collecte des ordures concurrent.S'il échoue à réclamer une page de
page_pool_lazily_freed, il essaiera de réclamer une page dethe page_pool_clean, qui contient des pages qui ont été mmapées lors d'une demande d'allocation de page précédente mais jamais accédées.Si la réclamation d'une page à partir de
pool_page_cleanet depage_pool_lazily_freeda échoué, elle essaiera de réclamer une page à partir depage_pool_freed, qui contient des pages qui ont déjà été conseillées par un thread GC de balayage concurrent et dont l'adresse virtuelle sous-jacente peut être recyclée.Si cela a échoué dans toutes les tentatives mentionnées ci-dessus, il va mmap un lot de pages, en revendiquer une pour lui-même, et insérer les pages restantes dans
page_pool_clean.
Marking and Generational Collection
La phase de marquage de Julia est implémentée par une recherche en profondeur itérative parallèle sur le graphe d'objets. Le collecteur de Julia est non mobile, donc les informations sur l'âge des objets ne peuvent pas être déterminées uniquement par la région mémoire dans laquelle l'objet réside, mais doivent être encodées d'une manière ou d'une autre dans l'en-tête de l'objet ou sur une table annexe. Les deux bits les plus bas de l'en-tête d'un objet sont utilisés pour stocker, respectivement, un bit de marquage qui est activé lorsqu'un objet est analysé pendant la phase de marquage et un bit d'âge pour la collecte générationnelle.
La collecte générationnelle est mise en œuvre par le biais de bits collants : les objets ne sont poussés sur la pile de marquage, et donc tracés, que si leurs bits de marquage ne sont pas définis. Lorsque les objets atteignent la génération la plus ancienne, leurs bits de marquage ne sont pas réinitialisés lors du soi-disant "nettoyage rapide", ce qui entraîne que ces objets ne sont pas tracés lors d'une phase de marquage ultérieure. Un "nettoyage complet", cependant, entraîne la réinitialisation des bits de marquage de tous les objets, ce qui conduit à ce que tous les objets soient tracés lors d'une phase de marquage ultérieure. Les objets sont promus à la génération suivante lors de chaque phase de nettoyage qu'ils survivent. Du côté du mutateur, les écritures de champ sont interceptées par une barrière d'écriture qui pousse l'adresse d'un objet dans un ensemble de souvenirs par thread si l'objet est dans la dernière génération, et si l'objet au champ en cours d'écriture ne l'est pas. Les objets dans cet ensemble de souvenirs sont ensuite tracés lors de la phase de marquage.
Sweeping
Le balayage des pools d'objets pour Julia peut se diviser en deux catégories : si une page donnée gérée par l'allocateur de pool contient au moins un objet vivant, alors une liste de libres doit être enfilée à travers ses objets morts ; si une page donnée ne contient aucun objet vivant, alors sa mémoire physique sous-jacente peut être retournée au système d'exploitation par, par exemple, l'utilisation d'appels système madvise sur Linux.
La première catégorie de balayage est parallélisée par le biais du vol de travail. Pour la deuxième catégorie de balayage, si le balayage de pages concurrent est activé via le drapeau --gcthreads=X,1, nous effectuons les appels système madvise dans un thread de balayage en arrière-plan, en parallèle avec les threads mutateurs. Pendant la phase d'arrêt du monde du collecteur, les pages allouées dans le pool qui ne contiennent aucun objet vivant sont initialement poussées dans le pool_page_lazily_freed. Le thread de balayage en arrière-plan est ensuite réveillé et est responsable de la suppression des pages du pool_page_lazily_freed, en appelant madvise sur celles-ci, et en les insérant dans le pool_page_freed. Comme décrit ci-dessus, le pool_page_lazily_freed est également partagé avec les threads mutateurs. Cela implique que sur des charges de travail multithreadées lourdes en allocation, les threads mutateurs éviteraient souvent un défaut de page lors de l'allocation (provenant de l'accès à une nouvelle page mmapée ou à une page madvisée) en allouant directement à partir d'une page dans le pool_page_lazily_freed, tandis que le thread de balayage en arrière-plan doit madviser un nombre réduit de pages étant donné que certaines d'entre elles ont déjà été revendiquées par les mutateurs.
Heuristics
Les heuristiques de GC ajustent le GC en modifiant la taille de l'intervalle d'allocation entre les collectes de déchets.
Les heuristiques du GC mesurent la taille du tas après une collecte et définissent la prochaine collecte selon l'algorithme décrit par https://dl.acm.org/doi/10.1145/3563323. En résumé, il soutient que la cible du tas devrait avoir une relation de racine carrée avec le tas vivant, et qu'elle devrait également être ajustée en fonction de la rapidité avec laquelle le GC libère des objets et de la rapidité avec laquelle les mutateurs allouent. Les heuristiques mesurent la taille du tas en comptant le nombre de pages qui sont en cours d'utilisation et les objets qui utilisent malloc. Auparavant, nous mesurions la taille du tas en comptant les objets vivants, mais cela ne tenait pas compte de la fragmentation, ce qui pourrait conduire à de mauvaises décisions. Cela signifiait également que nous utilisions des informations locales au thread (allocations) pour prendre des décisions concernant un processus global (quand faire le GC), mesurer les pages signifie que la décision est globale.
Le GC effectuera des collectes complètes lorsque la taille du tas atteindra 80 % de la taille maximale autorisée.