JIT Design and Implementation
Ce document explique la conception et la mise en œuvre du JIT de Julia, après que la génération de code soit terminée et que l'IR LLVM non optimisé ait été produit. Le JIT est responsable de l'optimisation et de la compilation de cet IR en code machine, ainsi que de son intégration dans le processus actuel et de la mise à disposition du code pour l'exécution.
Introduction
Le JIT est responsable de la gestion des ressources de compilation, de la recherche de code précédemment compilé et de la compilation de nouveau code. Il est principalement construit sur la technologie On-Request-Compilation d'LLVM (ORCv2), qui offre un support pour un certain nombre de fonctionnalités utiles telles que la compilation concurrente, la compilation paresseuse et la capacité de compiler du code dans un processus séparé. Bien qu'LLVM fournisse un compilateur JIT de base sous la forme de LLJIT, Julia utilise de nombreuses API ORCv2 directement pour créer son propre compilateur JIT personnalisé.
Overview
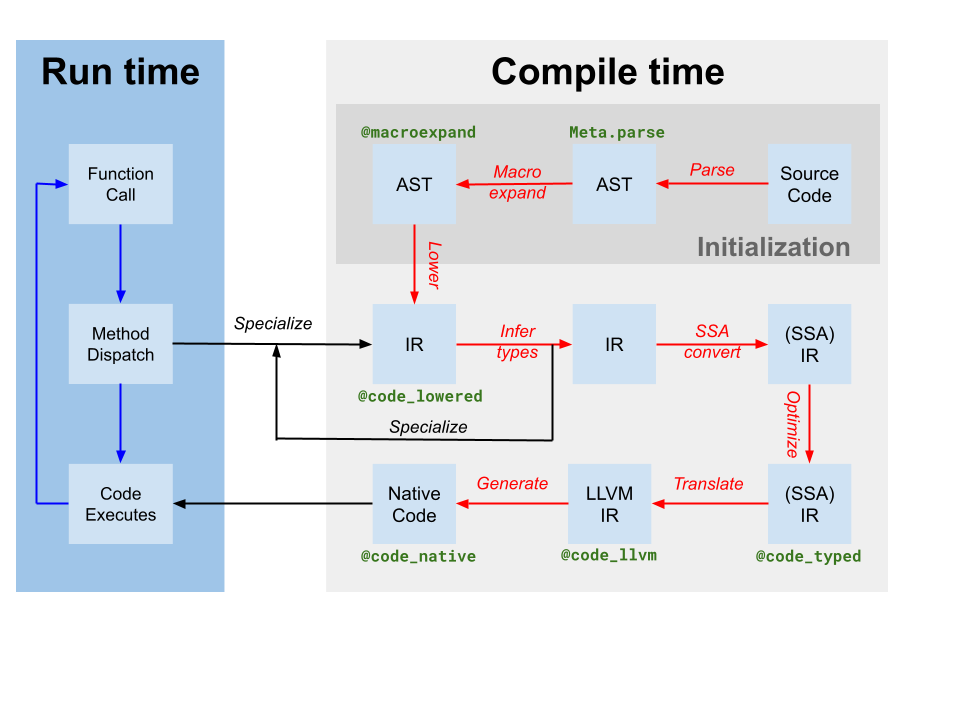
Codegen produit un module LLVM contenant du IR pour une ou plusieurs fonctions Julia à partir du IR SSA Julia original produit par l'inférence de type (étiqueté comme traduction sur le diagramme du compilateur ci-dessus). Il produit également une correspondance entre l'instance de code et le nom de la fonction LLVM. Cependant, bien que certaines optimisations aient été appliquées par le compilateur basé sur Julia sur le IR Julia, le IR LLVM produit par codegen contient encore de nombreuses opportunités d'optimisation. Ainsi, la première étape que le JIT effectue est d'exécuter un pipeline d'optimisation indépendant de la cible[tdp] sur le module LLVM. Ensuite, le JIT exécute un pipeline d'optimisation dépendant de la cible, qui inclut des optimisations spécifiques à la cible et la génération de code, et produit un fichier objet. Enfin, le JIT lie le fichier objet résultant au processus en cours et rend le code disponible pour l'exécution. Tout cela est contrôlé par du code dans src/jitlayers.cpp.
Actuellement, un seul thread à la fois est autorisé à entrer dans le pipeline d'optimisation-compilation-liaison, en raison des restrictions imposées par l'un de nos lieurs (RuntimeDyld). Cependant, le JIT est conçu pour prendre en charge l'optimisation et la compilation concurrentes, et la restriction du lieur devrait être levée à l'avenir lorsque RuntimeDyld aura été entièrement remplacé sur toutes les plateformes.
Optimization Pipeline
Le pipeline d'optimisation est basé sur le nouveau gestionnaire de passes d'LLVM, mais le pipeline est personnalisé pour les besoins de Julia. Le pipeline est défini dans src/pipeline.cpp, et se déroule en plusieurs étapes comme détaillé ci-dessous.
- Simplification précoce
- Ces passes sont principalement utilisées pour simplifier l'IR et canoniser les motifs afin que les passes ultérieures puissent identifier ces motifs plus facilement. De plus, divers appels intrinsèques tels que les indices de prédiction de branche et les annotations sont réduits en d'autres métadonnées ou d'autres caractéristiques de l'IR.
SimplifyCFG(simplifier le graphe de contrôle de flux),DCE(élimination de code mort), etSROA(remplacement scalaire des agrégats) sont quelques-uns des acteurs clés ici.
- Ces passes sont principalement utilisées pour simplifier l'IR et canoniser les motifs afin que les passes ultérieures puissent identifier ces motifs plus facilement. De plus, divers appels intrinsèques tels que les indices de prédiction de branche et les annotations sont réduits en d'autres métadonnées ou d'autres caractéristiques de l'IR.
- Optimisation précoce
- Ces passes sont généralement peu coûteuses et se concentrent principalement sur la réduction du nombre d'instructions dans l'IR et la propagation des connaissances à d'autres instructions. Par exemple,
EarlyCSEest utilisé pour effectuer l'élimination des sous-expressions communes, etInstCombineetInstSimplifyeffectuent un certain nombre de petites optimisations de peephole pour rendre les opérations moins coûteuses.
- Ces passes sont généralement peu coûteuses et se concentrent principalement sur la réduction du nombre d'instructions dans l'IR et la propagation des connaissances à d'autres instructions. Par exemple,
- Optimisation de boucle
- Ces passes canonisent et simplifient les boucles. Les boucles sont souvent du code chaud, ce qui rend l'optimisation des boucles extrêmement importante pour la performance. Les acteurs clés ici incluent
LoopRotate,LICM, etLoopFullUnroll. Certaines éliminations de vérification des limites se produisent également ici, en raison du passageIRCEqui peut prouver que certaines limites ne sont jamais dépassées.
- Ces passes canonisent et simplifient les boucles. Les boucles sont souvent du code chaud, ce qui rend l'optimisation des boucles extrêmement importante pour la performance. Les acteurs clés ici incluent
- Optimisation scalaire
- Le pipeline d'optimisation scalaire contient un certain nombre de passes plus coûteuses, mais plus puissantes, telles que
GVN(numérotation de valeur globale),SCCP(propagation conditionnelle constante sparse), et un autre tour d'élimination des vérifications de limites. Ces passes sont coûteuses, mais elles peuvent souvent supprimer de grandes quantités de code et rendre la vectorisation beaucoup plus réussie et efficace. Plusieurs autres passes de simplification et d'optimisation s'entremêlent avec les plus coûteuses pour réduire la quantité de travail qu'elles ont à faire.
- Le pipeline d'optimisation scalaire contient un certain nombre de passes plus coûteuses, mais plus puissantes, telles que
- Vectorisation
- Automatic vectorization est une transformation extrêmement puissante pour le code intensif en CPU. En bref, la vectorisation permet l'exécution d'une single instruction on multiple data (SIMD), par exemple, en effectuant 8 opérations d'addition en même temps. Cependant, prouver que le code est à la fois capable de vectorisation et rentable à vectoriser est difficile, et cela repose fortement sur les passes d'optimisation antérieures pour transformer l'IR dans un état où la vectorisation en vaut la peine.
- Baisse intrinsèque
- Julia insère un certain nombre d'intrinsèques personnalisées, pour des raisons telles que l'allocation d'objets, la collecte des ordures et la gestion des exceptions. Ces intrinsèques ont été initialement placées pour rendre les opportunités d'optimisation plus évidentes, mais elles sont maintenant abaissées en IR LLVM pour permettre à l'IR d'être émis en tant que code machine.
- Nettoyage
- Ces passes sont des optimisations de dernière chance et effectuent de petites optimisations telles que la propagation de multiplication-addition fusionnée et la simplification de division-reste. De plus, les cibles qui ne prennent pas en charge les nombres à virgule flottante de demi-précision verront leurs instructions de demi-précision converties en instructions de simple précision ici, et des passes sont ajoutées pour fournir un support de désinfection.
Target-Dependent Optimization and Code Generation
LLVM fournit une optimisation et une génération de code machine dépendantes de la cible dans le même pipeline, situé dans le TargetMachine pour une plateforme donnée. Ces passes incluent la sélection d'instructions, la planification d'instructions, l'allocation de registres et l'émission de code machine. La documentation LLVM offre un bon aperçu du processus, et le code source LLVM est le meilleur endroit pour chercher des détails sur le pipeline et les passes.
Linking
Actuellement, Julia est en train de passer entre deux linkers : l'ancien linker RuntimeDyld et le nouveau linker JITLink. JITLink contient un certain nombre de fonctionnalités que RuntimeDyld n'a pas, telles que le linking concurrent et réentrant, mais manque actuellement d'un bon support pour les intégrations de profilage et ne prend pas encore en charge toutes les plateformes que RuntimeDyld prend en charge. Au fil du temps, JITLink devrait remplacer complètement RuntimeDyld. D'autres détails sur JITLink peuvent être trouvés dans la documentation LLVM.
Execution
Une fois que le code a été lié au processus actuel, il est disponible pour exécution. Ce fait est porté à la connaissance du code générant codeinst en mettant à jour les champs invoke, specsigflags et specptr de manière appropriée. Les codeinsts prennent en charge la mise à niveau des champs invoke, specsigflags et specptr, tant que chaque combinaison de ces champs qui existe à un moment donné est valide pour être appelée. Cela permet au JIT de mettre à jour ces champs sans invalider les codeinsts existants, soutenant un potentiel JIT concurrent futur. Plus précisément, les états suivants peuvent être valides :
invokeest NULL,specsigflagsest 0b00,specptrest NULL- Ceci est l'état initial d'un codeinst, et indique que le codeinst n'a pas encore été compilé.
invoken'est pas nul,specsigflagsest 0b00,specptrest NULL- Cela indique que le codeinst n'a pas été compilé avec une spécialisation, et que le codeinst doit être invoqué directement. Notez que dans ce cas,
invokene lit ni les champsspecsigflagsnispecptr, et par conséquent, ils peuvent être modifiés sans invalider le pointeurinvoke.
- Cela indique que le codeinst n'a pas été compilé avec une spécialisation, et que le codeinst doit être invoqué directement. Notez que dans ce cas,
invokeest non nul,specsigflagsest 0b10,specptrest non nul- Cela indique que le code a été compilé, mais qu'une signature de fonction spécialisée a été jugée inutile par le codegen.
invokeest non nul,specsigflagsest 0b11,specptrest non nul- Cela indique que le codeinst a été compilé et qu'une signature de fonction spécialisée a été jugée nécessaire par le codegen. Le champ
specptrcontient un pointeur vers la signature de fonction spécialisée. Le pointeurinvokeest autorisé à lire à la fois les champsspecsigflagsetspecptr.
- Cela indique que le codeinst a été compilé et qu'une signature de fonction spécialisée a été jugée nécessaire par le codegen. Le champ
De plus, il existe un certain nombre d'états transitoires différents qui se produisent pendant le processus de mise à jour. Pour tenir compte de ces situations potentielles, les modèles d'écriture et de lecture suivants doivent être utilisés lors de la gestion de ces champs codeinst.
- Lors de l'écriture de
invoke,specsigflagsetspecptr:- Effectuez une opération de comparaison-échange atomique de specptr en supposant que l'ancienne valeur était NULL. Cette opération de comparaison-échange doit avoir au moins un ordre d'acquisition-libération, afin de fournir des garanties d'ordre des opérations mémoire restantes dans l'écriture.
- Si
specptrn'était pas nul, cessez l'opération d'écriture et attendez que le bit 0b10 despecsigflagssoit écrit. - Écrivez le nouveau bit bas de
specsigflagsà sa valeur finale. Cela peut être une écriture relâchée. - Écrivez le nouveau pointeur
invokeà sa valeur finale. Cela doit avoir au moins un ordre de mémoire de libération pour se synchroniser avec les lectures deinvoke. - Définissez le deuxième bit de
specsigflagssur 1. Cela doit être au moins un ordre de mémoire de libération pour se synchroniser avec les lectures despecsigflags. Cette étape complète l'opération d'écriture et annonce à tous les autres threads que tous les champs ont été définis.
- Lors de la lecture de
invoke,specsigflagsetspecptr:- Lisez le champ
invokeavec au moins un ordre de mémoire d'acquisition. Ce chargement sera appeléinitial_invoke. - Si
initial_invokeest NULL, le codeinst n'est pas encore exécutable.invokeest NULL,specsigflagspeut être traité comme 0b00,specptrpeut être traité comme NULL. - Lisez le champ
specptravec au moins un ordre de mémoire d'acquisition. - Si
specptrest NULL, alors le pointeurinitial_invokene doit pas dépendre despecptrpour garantir une exécution correcte. Par conséquent,invokeest non nul,specsigflagspeut être traité comme 0b00,specptrpeut être traité comme NULL. - Si
specptrn'est pas nul, alorsinitial_invokepourrait ne pas être le champinvokefinal qui utilisespecptr. Cela peut se produire sispecptra été écrit, mais queinvoken'a pas encore été écrit. Par conséquent, tournez sur le deuxième bit despecsigflagsjusqu'à ce qu'il soit défini sur 1 avec au moins un ordre de mémoire d'acquisition. - Relisez le champ
invokeavec au moins un ordre de mémoire d'acquisition. Ce chargement sera appeléfinal_invoke. - Lisez le champ
specsigflagsavec n'importe quel ordre de mémoire. invokeestfinal_invoke,specsigflagsest la valeur lue à l'étape 7,specptrest la valeur lue à l'étape 3.
- Lisez le champ
- Lors de la mise à jour d'un
specptrvers un autre pointeur de fonction différent mais équivalent :- Effectuez un stockage de libération du nouveau pointeur de fonction vers
specptr. Les courses ici doivent être bénignes, car l'ancien pointeur de fonction doit rester valide, et tous les nouveaux doivent également être valides. Une fois qu'un pointeur a été écrit dansspecptr, il doit toujours être appelable, qu'il soit ou non écrasé par la suite.
- Effectuez un stockage de libération du nouveau pointeur de fonction vers
Bien que ces étapes d'écriture, de lecture et de mise à jour soient compliquées, elles garantissent que le JIT peut mettre à jour les codeinsts sans invalider les codeinsts existants, et que le JIT peut mettre à jour les codeinsts sans invalider les pointeurs invoke existants. Cela permet au JIT de potentiellement réoptimiser les fonctions à des niveaux d'optimisation plus élevés à l'avenir, et permettra également au JIT de prendre en charge la compilation concurrente des fonctions à l'avenir.
- tdpThis is not a totally-target independent pipeline, as transformations such as vectorization rely upon target information such as vector register width and cost modeling. Additionally, codegen itself makes a few target-dependent assumptions, and the optimization pipeline will take advantage of that knowledge.