Inference
How inference works
Dans le compilateur Julia, "l'inférence de type" fait référence au processus de déduction des types des valeurs ultérieures à partir des types des valeurs d'entrée. L'approche de Julia en matière d'inférence a été décrite dans les articles de blog ci-dessous :
- Shows a simplified implementation of the data-flow analysis algorithm, that Julia's type inference routine is based on.
- Gives a high level view of inference with a focus on its inter-procedural convergence guarantee.
- Explains a refinement on the algorithm introduced in 2.
Debugging compiler.jl
Vous pouvez démarrer une session Julia, modifier compiler/*.jl (par exemple pour insérer des instructions print), puis remplacer Core.Compiler dans votre session en cours en naviguant vers base et en exécutant include("compiler/compiler.jl"). Cette astuce conduit généralement à un développement beaucoup plus rapide que si vous reconstruisez Julia pour chaque changement.
Alternativement, vous pouvez utiliser le package Revise.jl pour suivre les modifications du compilateur en utilisant la commande Revise.track(Core.Compiler) au début de votre session Julia. Comme expliqué dans le Revise documentation, les modifications apportées au compilateur seront reflétées lorsque les fichiers modifiés seront enregistrés.
Un point d'entrée pratique pour l'inférence est typeinf_code. Voici une démonstration exécutant l'inférence sur convert(Int, UInt(1)) :
# Get the method
atypes = Tuple{Type{Int}, UInt} # argument types
mths = methods(convert, atypes) # worth checking that there is only one
m = first(mths)
# Create variables needed to call `typeinf_code`
interp = Core.Compiler.NativeInterpreter()
sparams = Core.svec() # this particular method doesn't have type-parameters
run_optimizer = true # run all inference optimizations
types = Tuple{typeof(convert), atypes.parameters...} # Tuple{typeof(convert), Type{Int}, UInt}
Core.Compiler.typeinf_code(interp, m, types, sparams, run_optimizer)Si vos aventures de débogage nécessitent un MethodInstance, vous pouvez le rechercher en appelant Core.Compiler.specialize_method en utilisant plusieurs des variables ci-dessus. Un objet CodeInfo peut être obtenu avec
# Returns the CodeInfo object for `convert(Int, ::UInt)`:
ci = (@code_typed convert(Int, UInt(1)))[1]The inlining algorithm (inline_worthy)
Une grande partie du travail le plus difficile pour l'inlining se déroule dans ssa_inlining_pass!. Cependant, si votre question est "pourquoi ma fonction ne s'est-elle pas inlinée ?", vous serez très probablement intéressé par inline_worthy, qui prend la décision d'inliner l'appel de fonction ou non.
inline_worthy implémente un modèle de coût, où les fonctions "bon marché" sont intégrées ; plus précisément, nous intégrons des fonctions si leur temps d'exécution anticipé n'est pas grand par rapport au temps qu'il faudrait pour issue a call si elles n'étaient pas intégrées. Le modèle de coût est extrêmement simple et ignore de nombreux détails importants : par exemple, toutes les boucles for sont analysées comme si elles allaient être exécutées une seule fois, et le coût d'un if...else...end inclut le coût total de toutes les branches. Il convient également de reconnaître que nous manquons actuellement d'un ensemble de fonctions adaptées pour tester à quel point le modèle de coût prédit le coût réel d'exécution, bien que BaseBenchmarks fournisse une grande quantité d'informations indirectes sur les succès et les échecs de toute modification de l'algorithme d'inlining.
La base du modèle de coût est une table de recherche, implémentée dans add_tfunc et ses appelants, qui attribue un coût estimé (mesuré en cycles CPU) à chacune des fonctions intrinsèques de Julia. Ces coûts sont basés sur standard ranges for common architectures (voir Agner Fog's analysis pour plus de détails).
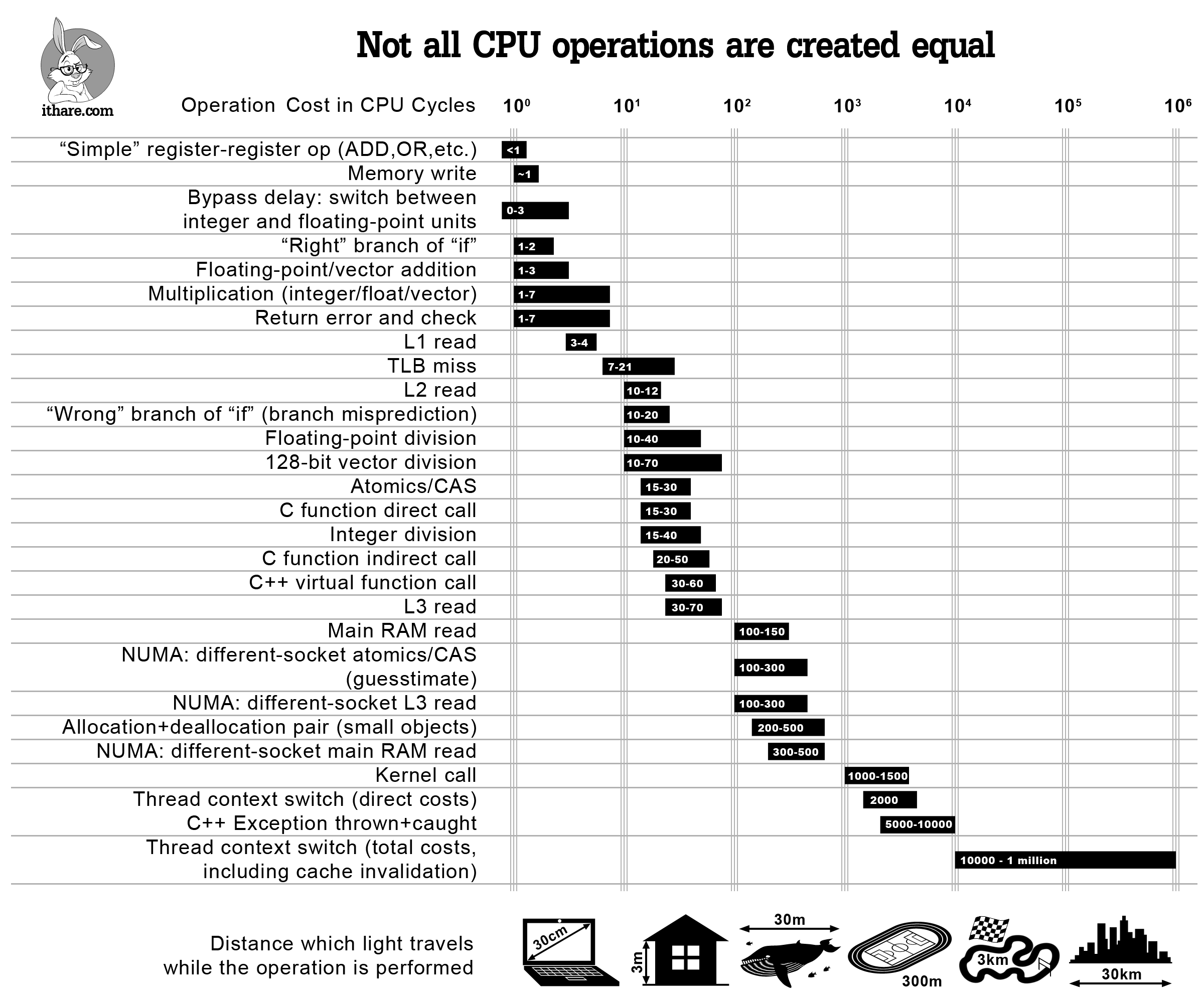{kind=link}
Nous complétons cette table de recherche de bas niveau avec un certain nombre de cas spéciaux. Par exemple, une expression :invoke (un appel pour lequel tous les types d'entrée et de sortie ont été inférés à l'avance) se voit attribuer un coût fixe (actuellement 20 cycles). En revanche, une expression :call, pour des fonctions autres que les intrinsics/builtins, indique que l'appel nécessitera un dispatch dynamique, auquel cas nous attribuons un coût défini par Params.inline_nonleaf_penalty (actuellement fixé à 1000). Notez qu'il ne s'agit pas d'une estimation "première-principes" du coût brut du dispatch dynamique, mais d'une simple heuristique indiquant que le dispatch dynamique est extrêmement coûteux.
Chaque déclaration est analysée pour son coût total dans une fonction appelée statement_cost. Vous pouvez afficher le coût associé à chaque déclaration comme suit :
julia> Base.print_statement_costs(stdout, map, (typeof(sqrt), Tuple{Int},)) # map(sqrt, (2,))
map(f, t::Tuple{Any}) @ Base tuple.jl:281
0 1 ─ %1 = $(Expr(:boundscheck, true))::Bool
0 │ %2 = Base.getfield(_3, 1, %1)::Int64
1 │ %3 = Base.sitofp(Float64, %2)::Float64
0 │ %4 = Base.lt_float(%3, 0.0)::Bool
0 └── goto #3 if not %4
0 2 ─ invoke Base.Math.throw_complex_domainerror(:sqrt::Symbol, %3::Float64)::Union{}
0 └── unreachable
20 3 ─ %8 = Base.Math.sqrt_llvm(%3)::Float64
0 └── goto #4
0 4 ─ goto #5
0 5 ─ %11 = Core.tuple(%8)::Tuple{Float64}
0 └── return %11
Les coûts de ligne sont dans la colonne de gauche. Cela inclut les conséquences de l'inlining et d'autres formes d'optimisation.