JIT Design and Implementation
この文書は、コード生成が完了し、最適化されていないLLVM IRが生成された後のJuliaのJITの設計と実装について説明しています。JITは、このIRを最適化して機械コードにコンパイルし、現在のプロセスにリンクしてコードを実行可能にする責任を負っています。
Introduction
JITは、コンパイルリソースの管理、以前にコンパイルされたコードの検索、新しいコードのコンパイルを担当しています。これは主にLLVMのOn-Request-Compilation(ORCv2)技術に基づいており、同時コンパイル、遅延コンパイル、別プロセスでのコードコンパイルの能力など、いくつかの便利な機能をサポートしています。LLVMはLLJITの形で基本的なJITコンパイラを提供していますが、Juliaは多くのORCv2 APIを直接使用して独自のカスタムJITコンパイラを作成しています。
Overview
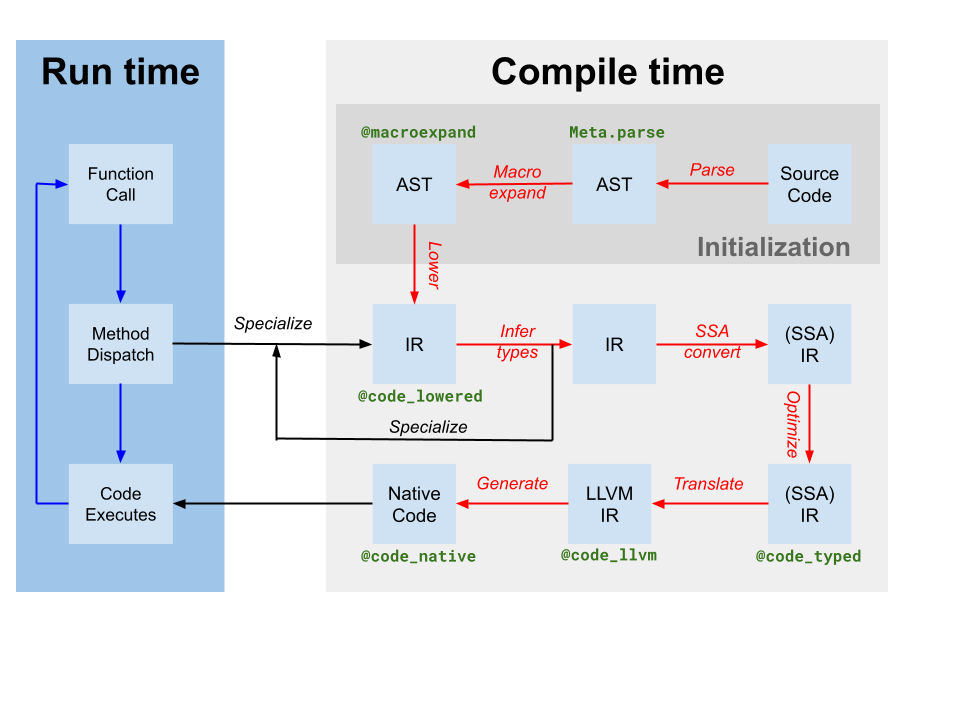
Codegenは、型推論によって生成された元のJulia SSA IRから1つまたは複数のJulia関数のIRを含むLLVMモジュールを生成します(上記のコンパイラ図でtranslateとしてラベル付けされています)。また、コードインスタンスとLLVM関数名のマッピングも生成します。しかし、JuliaベースのコンパイラがJulia IRに対していくつかの最適化を適用したにもかかわらず、codegenによって生成されたLLVM IRにはまだ多くの最適化の機会が含まれています。したがって、JITが最初に行うステップは、LLVMモジュールに対してターゲット非依存の最適化パイプライン[tdp]を実行することです。次に、JITはターゲット依存の最適化パイプラインを実行し、ターゲット固有の最適化とコード生成を含み、オブジェクトファイルを出力します。最後に、JITは生成されたオブジェクトファイルを現在のプロセスにリンクし、コードを実行可能にします。これらすべては、src/jitlayers.cppのコードによって制御されています。
現在、最適化-コンパイル-リンクパイプラインには、一度に1つのスレッドのみが入ることが許可されています。これは、私たちのリンカーの1つ(RuntimeDyld)によって課せられた制限によるものです。しかし、JITは同時最適化とコンパイルをサポートするように設計されており、RuntimeDyldがすべてのプラットフォームで完全に置き換えられると、リンカーの制限は将来的に解除されると期待されています。
Optimization Pipeline
最適化パイプラインはLLVMの新しいパスマネージャに基づいていますが、パイプラインはJuliaのニーズに合わせてカスタマイズされています。パイプラインはsrc/pipeline.cppで定義されており、以下に詳述するいくつかのステージを通じて進行します。
初期の簡素化
- これらのパスは、主にIRを簡素化し、パターンを標準化するために使用され、後のパスがそれらのパターンをより簡単に特定できるようにします。さらに、分岐予測ヒントや注釈などのさまざまな内在的呼び出しは、他のメタデータや他のIR機能に変換されます。
SimplifyCFG(制御フローグラフの簡素化)、DCE(デッドコードの排除)、およびSROA(集約のスカラー置換)は、ここでの重要なプレーヤーのいくつかです。
- これらのパスは、主にIRを簡素化し、パターンを標準化するために使用され、後のパスがそれらのパターンをより簡単に特定できるようにします。さらに、分岐予測ヒントや注釈などのさまざまな内在的呼び出しは、他のメタデータや他のIR機能に変換されます。
早期最適化
- これらのパスは通常安価であり、主にIR内の命令数を減らし、他の命令に知識を伝播させることに焦点を当てています。例えば、
EarlyCSEは共通部分式の消去を行うために使用され、InstCombineおよびInstSimplifyは、操作をより安価にするためのいくつかの小さなピーphole最適化を実行します。
- これらのパスは通常安価であり、主にIR内の命令数を減らし、他の命令に知識を伝播させることに焦点を当てています。例えば、
ループ最適化
- これらのパスはループを正準化し、簡素化します。ループはしばしばホットコードであり、ループ最適化はパフォーマンスにとって非常に重要です。ここでの主要なプレーヤーには
LoopRotate、LICM、およびLoopFullUnrollが含まれます。また、IRCEパスの結果として、特定の境界が決して超えられないことを証明できるため、いくつかの境界チェックの排除もここで発生します。
- これらのパスはループを正準化し、簡素化します。ループはしばしばホットコードであり、ループ最適化はパフォーマンスにとって非常に重要です。ここでの主要なプレーヤーには
スカラー最適化
ベクトル化
- Automatic vectorization は、CPU集中的なコードに対して非常に強力な変換です。簡単に言うと、ベクトル化は single instruction on multiple data (SIMD) の実行を可能にし、例えば8つの加算操作を同時に行うことができます。しかし、コードがベクトル化可能であり、かつベクトル化する価値があることを証明するのは難しく、これは主に事前の最適化パスに依存してIRをベクトル化する価値のある状態に整えることに依存しています。
内因的低下
- Juliaは、オブジェクトの割り当て、ガーベジコレクション、例外処理などの理由から、いくつかのカスタムインストリンシックを挿入します。これらのインストリンシックは、最適化の機会をより明確にするために元々配置されましたが、現在はLLVM IRに低下され、IRが機械コードとして出力されることを可能にしています。
クリーンアップ
- これらのパスは最後のチャンスの最適化であり、融合乗算加算伝播や除算余り簡略化などの小さな最適化を実行します。さらに、半精度浮動小数点数をサポートしないターゲットでは、半精度命令がここで単精度命令に変換され、サニタイザサポートを提供するためのパスが追加されます。
Target-Dependent Optimization and Code Generation
LLVMは、特定のプラットフォームのTargetMachine内で、ターゲット依存の最適化と機械コード生成を同じパイプラインで提供します。これらのパスには、命令選択、命令スケジューリング、レジスタ割り当て、機械コードの発行が含まれます。LLVMのドキュメントはこのプロセスの良い概要を提供しており、LLVMのソースコードはパイプラインとパスの詳細を確認するための最良の場所です。
Linking
現在、Juliaは古いRuntimeDyldリンカーと新しいJITLinkリンカーの間で移行しています。JITLinkには、RuntimeDyldにはないいくつかの機能が含まれており、同時リンクや再入可能リンクなどがありますが、現在はプロファイリング統合の良好なサポートが欠けており、RuntimeDyldがサポートするすべてのプラットフォームをまだサポートしていません。時間が経つにつれて、JITLinkはRuntimeDyldを完全に置き換えることが期待されています。JITLinkに関する詳細はLLVMのドキュメントに記載されています。
Execution
コードが現在のプロセスにリンクされると、それは実行可能になります。この事実は、invoke、specsigflags、および specptr フィールドを適切に更新することによって生成コードインスタンスに知らされます。コードインスタンスは、これらのフィールドのすべての組み合わせが任意の時点で有効である限り、invoke、specsigflags、および specptr フィールドのアップグレードをサポートします。これにより、JITは既存のコードインスタンスを無効にすることなくこれらのフィールドを更新でき、将来の並行JITをサポートします。具体的には、以下の状態が有効である可能性があります:
invokeはNULLであり、specsigflagsは0b00で、specptrはNULLです。- これはコードインスタンスの初期状態であり、コードインスタンスがまだコンパイルされていないことを示しています。
invokeは非NULLで、specsigflagsは0b00、specptrはNULLです。- これは、codeinstが特別化なしでコンパイルされておらず、codeinstを直接呼び出すべきであることを示しています。この場合、
invokeはspecsigflagsまたはspecptrフィールドを読み取らないため、これらはinvokeポインタを無効にすることなく変更できます。
- これは、codeinstが特別化なしでコンパイルされておらず、codeinstを直接呼び出すべきであることを示しています。この場合、
invokeは非nullで、specsigflagsは0b10で、specptrは非nullです。- これは、codeinstがコンパイルされたことを示していますが、codegenによって特別な関数シグネチャは不要と見なされました。
invokeは非nullであり、specsigflagsは0b11であり、specptrは非nullです。- これは、codeinstがコンパイルされ、codegenによって特化した関数シグネチャが必要であると見なされたことを示しています。
specptrフィールドには、特化した関数シグネチャへのポインタが含まれています。invokeポインタは、specsigflagsおよびspecptrフィールドの両方を読み取ることが許可されています。
- これは、codeinstがコンパイルされ、codegenによって特化した関数シグネチャが必要であると見なされたことを示しています。
さらに、更新プロセス中に発生するさまざまな遷移状態があります。これらの潜在的な状況に対処するために、これらの codeinst フィールドを扱う際には、以下の書き込みおよび読み取りパターンを使用する必要があります。
invoke、specsigflags、およびspecptrを記述する際には:- NULLだったと仮定してspecptrのアトミックな比較交換操作を実行します。この比較交換操作は、書き込みの残りのメモリ操作に対する順序保証を提供するために、少なくともアクワイア-リリース順序を持つ必要があります。
specptrが非NULLの場合、書き込み操作を中止し、specsigflagsのビット0b10が書き込まれるのを待ちます。specsigflagsの新しい低ビットを最終値に書き込みます。これは緩やかな書き込みである可能性があります。- 新しい
invokeポインタを最終値に設定します。これは、invokeの読み取りと同期するために、少なくともリリースメモリ順序を持っている必要があります。 specsigflagsの2番目のビットを1に設定します。これは、specsigflagsの読み取りと同期するために、少なくともリリースメモリ順序である必要があります。このステップは書き込み操作を完了し、すべての他のスレッドにすべてのフィールドが設定されたことを通知します。
invoke、specsigflags、およびspecptrをすべて読むとき:invokeフィールドを、少なくとも取得メモリ順序で読み取ります。この読み取りはinitial_invokeと呼ばれます。initial_invokeがNULLの場合、codeinstはまだ実行可能ではありません。invokeはNULLであり、specsigflagsは0b00として扱うことができ、specptrはNULLとして扱うことができます。specptrフィールドを少なくとも取得メモリ順序で読み取ります。specptrが NULL の場合、initial_invokeポインタは正しい実行を保証するためにspecptrに依存してはなりません。したがって、invokeは非 NULL であり、specsigflagsは 0b00 として扱うことができ、specptrは NULL として扱うことができます。specptrが非NULLである場合、initial_invokeはspecptrを使用する最終的なinvokeフィールドではない可能性があります。これは、specptrが書き込まれたが、invokeがまだ書き込まれていない場合に発生する可能性があります。したがって、少なくとも取得メモリ順序で1に設定されるまで、specsigflagsの2番目のビットでスピンします。invokeフィールドを少なくとも取得メモリ順序で再読み込みします。このロードはfinal_invokeと呼ばれます。specsigflagsフィールドを任意のメモリ順序で読み取ります。invokeはfinal_invoke、specsigflagsはステップ 7 で読み取った値、specptrはステップ 3 で読み取った値です。
specptrを異なるが同等の関数ポインタに更新する場合:- 新しい関数ポインタを
specptrにリリースストアを実行します。ここでの競合は無害でなければならず、古い関数ポインタは依然として有効である必要があり、新しいポインタも有効である必要があります。specptrにポインタが書き込まれた後は、それが上書きされるかどうかにかかわらず、常に呼び出し可能でなければなりません。
- 新しい関数ポインタを
これらの書き込み、読み取り、および更新のステップは複雑ですが、JITが既存のcodeinstを無効にすることなくcodeinstを更新できること、また既存のinvokeポインタを無効にすることなくcodeinstを更新できることを保証します。これにより、JITは将来的により高い最適化レベルで関数を再最適化する可能性があり、また将来的には関数の同時コンパイルをサポートすることができます。
- tdpThis is not a totally-target independent pipeline, as transformations such as vectorization rely upon target information such as vector register width and cost modeling. Additionally, codegen itself makes a few target-dependent assumptions, and the optimization pipeline will take advantage of that knowledge.