Profiling
Profileモジュールは、開発者がコードのパフォーマンスを向上させるためのツールを提供します。使用すると、実行中のコードの測定を行い、個々の行にどれだけの時間が費やされているかを理解するのに役立つ出力を生成します。最も一般的な使用法は、最適化のターゲットとして「ボトルネック」を特定することです。
Profile は「サンプリング」として知られるものを実装しています。statistical profiler。これは、任意のタスクの実行中に定期的にバックトレースを取得することによって機能します。各バックトレースは、現在実行中の関数と行番号、さらにこの行に至るまでの関数呼び出しの完全なチェーンをキャプチャし、したがって現在の実行状態の「スナップショット」となります。
もしあなたの実行時間の多くが特定のコード行の実行に費やされている場合、この行はすべてのバックトレースのセットに頻繁に表示されます。言い換えれば、特定の行の「コスト」—実際には、この行を含む関数呼び出しのシーケンスのコスト—は、すべてのバックトレースのセットにどれだけ頻繁に現れるかに比例します。
サンプリングプロファイラは、完全な行単位のカバレッジを提供しません。なぜなら、バックトレースは間隔で発生するからです(デフォルトでは、Unixシステムでは1ミリ秒、Windowsでは10ミリ秒ですが、実際のスケジューリングはオペレーティングシステムの負荷に依存します)。さらに、以下で詳しく説明するように、サンプルはすべての実行ポイントのスパースなサブセットで収集されるため、サンプリングプロファイラによって収集されたデータは統計的ノイズの影響を受けます。
これらの制限にもかかわらず、サンプリングプロファイラには substantial strengths があります:
- コードに変更を加える必要はなく、タイミング測定を行うことができます。
- それはJuliaのコアコードにプロファイルし、さらには(オプションで)CおよびFortranライブラリにプロファイルすることができます。
- 「不頻繁に」実行することで、パフォーマンスのオーバーヘッドは非常に少なくなります。プロファイリング中は、コードはほぼネイティブスピードで実行されることができます。
これらの理由から、代替手段を検討する前に、組み込みのサンプリングプロファイラーを使用してみることをお勧めします。
Basic usage
テストケースを使って作業しましょう:
julia> function myfunc()
A = rand(200, 200, 400)
maximum(A)
endコードをプロファイルする予定のものを少なくとも一度は実行するのが良いアイデアです(JuliaのJITコンパイラをプロファイルしたい場合を除いて):
julia> myfunc() # run once to force compilationこの関数のプロファイリングを行う準備が整いました:
julia> using Profile
julia> @profile myfunc()プロファイリング結果を見るために、いくつかのグラフィカルブラウザがあります。「ファミリー」としてのビジュアライザーの一つは FlameGraphs.jl に基づいており、各ファミリーメンバーは異なるユーザーインターフェースを提供しています:
- VS Code は、プロファイルの視覚化をサポートするフルIDEです。
- ProfileView.jl は、GTKに基づいたスタンドアロンのビジュアライザーです。
- ProfileVega.jl はVegaLightを使用しており、Jupyterノートブックと良く統合されています。
- StatProfilerHTML.jl はHTMLを生成し、いくつかの追加の要約を提示し、Jupyterノートブックとの統合も優れています。
- ProfileSVG.jl はSVGをレンダリングします。
- PProf.jl は、グラフ、フレームグラフなどを検査するためのローカルウェブサイトを提供します。
- ProfileCanvas.jl は、Julia VS Code extension によって使用されるHTMLキャンバスベースのプロフィールビューアUIであり、インタラクティブなHTMLファイルを生成することもできます。
完全に独立したプロファイル可視化のアプローチは PProf.jl であり、外部の pprof ツールを使用します。
ここでは、標準ライブラリに付属するテキストベースの表示を使用します:
julia> Profile.print()
80 ./event.jl:73; (::Base.REPL.##1#2{Base.REPL.REPLBackend})()
80 ./REPL.jl:97; macro expansion
80 ./REPL.jl:66; eval_user_input(::Any, ::Base.REPL.REPLBackend)
80 ./boot.jl:235; eval(::Module, ::Any)
80 ./<missing>:?; anonymous
80 ./profile.jl:23; macro expansion
52 ./REPL[1]:2; myfunc()
38 ./random.jl:431; rand!(::MersenneTwister, ::Array{Float64,3}, ::Int64, ::Type{B...
38 ./dSFMT.jl:84; dsfmt_fill_array_close_open!(::Base.dSFMT.DSFMT_state, ::Ptr{F...
14 ./random.jl:278; rand
14 ./random.jl:277; rand
14 ./random.jl:366; rand
14 ./random.jl:369; rand
28 ./REPL[1]:3; myfunc()
28 ./reduce.jl:270; _mapreduce(::Base.#identity, ::Base.#scalarmax, ::IndexLinear,...
3 ./reduce.jl:426; mapreduce_impl(::Base.#identity, ::Base.#scalarmax, ::Array{F...
25 ./reduce.jl:428; mapreduce_impl(::Base.#identity, ::Base.#scalarmax, ::Array{F...この表示の各行は、コード内の特定のスポット(行番号)を表しています。インデントは関数呼び出しのネストされたシーケンスを示すために使用されており、よりインデントされた行は呼び出しのシーケンスの深い位置にあります。各行の最初の「フィールド」は、この行またはこの行によって実行された関数内で取得されたバックトレース(サンプル)の数です。第二のフィールドはファイル名と行番号、第三のフィールドは関数名です。特定の行番号はJuliaのコードが変更されるにつれて変わる可能性があることに注意してください。追跡したい場合は、この例を自分で実行するのが最良です。
この例では、最上位の関数が event.jl ファイルにあることがわかります。これは、Juliaを起動したときにREPLを実行する関数です。REPL.jl の97行目を調べると、ここで eval_user_input() 関数が呼び出されているのがわかります。これは、REPLで入力した内容を評価する関数であり、インタラクティブに作業しているため、@profile myfunc() を入力したときにこれらの関数が呼び出されました。次の行は、@profile マクロで行われたアクションを反映しています。
最初の行は、event.jlの73行目で80のバックトレースが取得されたことを示していますが、この行自体が「高コスト」であったわけではありません。3行目は、これら80のバックトレースが実際にはeval_user_inputへの呼び出しの内部でトリガーされたことを明らかにしています。どの操作が実際に時間を要しているのかを見つけるためには、呼び出しチェーンをさらに深く掘り下げる必要があります。
この出力の最初の「重要な」行は次のとおりです:
52 ./REPL[1]:2; myfunc()REPLは、myfuncをファイルに入れるのではなく、REPLで定義したことを指します。ファイルを使用していた場合、ここにはファイル名が表示されていたでしょう。[1]は、関数myfuncがこのREPLセッションで最初に評価された式であることを示しています。myfunc()の2行目にはrandへの呼び出しが含まれており、この行で52回(80のうち)のバックトレースが発生しました。その下には、dSFMT.jl内のdsfmt_fill_array_close_open!への呼び出しが見えます。
少し下に行くと、次のように見えます:
28 ./REPL[1]:3; myfunc()myfuncの3行目にはmaximumへの呼び出しが含まれており、ここで28(80のうち)のバックトレースが取得されました。その下には、このタイプの入力データに対するmaximum関数で時間のかかる操作を実行するbase/reduce.jl内の具体的な場所が表示されています。
全体として、ランダムな数を生成することは、最大要素を見つけることの約2倍のコストがかかると仮定的に結論付けることができます。この結果に対する信頼性を高めるために、より多くのサンプルを収集することができます:
julia> @profile (for i = 1:100; myfunc(); end)
julia> Profile.print()
[....]
3821 ./REPL[1]:2; myfunc()
3511 ./random.jl:431; rand!(::MersenneTwister, ::Array{Float64,3}, ::Int64, ::Type...
3511 ./dSFMT.jl:84; dsfmt_fill_array_close_open!(::Base.dSFMT.DSFMT_state, ::Ptr...
310 ./random.jl:278; rand
[....]
2893 ./REPL[1]:3; myfunc()
2893 ./reduce.jl:270; _mapreduce(::Base.#identity, ::Base.#scalarmax, ::IndexLinea...
[....]一般的に、ラインで収集された N サンプルがある場合、他のノイズ源(コンピュータが他のタスクで忙しい場合など)を除けば、sqrt(N) のオーダーの不確実性が期待できます。このルールの主な例外はガーベジコレクションで、これは頻繁には実行されませんが、かなりコストがかかる傾向があります。(JuliaのガーベジコレクタはCで書かれているため、以下に説明する C=true 出力モードを使用するか、ProfileView.jl を使用することで、そのようなイベントを検出できます。)
これはデフォルトの「ツリー」ダンプを示しています。代替として「フラット」ダンプがあり、ネストに依存せずにカウントを累積します。
julia> Profile.print(format=:flat)
Count File Line Function
6714 ./<missing> -1 anonymous
6714 ./REPL.jl 66 eval_user_input(::Any, ::Base.REPL.REPLBackend)
6714 ./REPL.jl 97 macro expansion
3821 ./REPL[1] 2 myfunc()
2893 ./REPL[1] 3 myfunc()
6714 ./REPL[7] 1 macro expansion
6714 ./boot.jl 235 eval(::Module, ::Any)
3511 ./dSFMT.jl 84 dsfmt_fill_array_close_open!(::Base.dSFMT.DSFMT_s...
6714 ./event.jl 73 (::Base.REPL.##1#2{Base.REPL.REPLBackend})()
6714 ./profile.jl 23 macro expansion
3511 ./random.jl 431 rand!(::MersenneTwister, ::Array{Float64,3}, ::In...
310 ./random.jl 277 rand
310 ./random.jl 278 rand
310 ./random.jl 366 rand
310 ./random.jl 369 rand
2893 ./reduce.jl 270 _mapreduce(::Base.#identity, ::Base.#scalarmax, :...
5 ./reduce.jl 420 mapreduce_impl(::Base.#identity, ::Base.#scalarma...
253 ./reduce.jl 426 mapreduce_impl(::Base.#identity, ::Base.#scalarma...
2592 ./reduce.jl 428 mapreduce_impl(::Base.#identity, ::Base.#scalarma...
43 ./reduce.jl 429 mapreduce_impl(::Base.#identity, ::Base.#scalarma...もしあなたのコードに再帰が含まれている場合、混乱を招く可能性のある点は、「子」関数内の行が、全体のバックトレースよりも多くのカウントを蓄積することがあるということです。次の関数定義を考えてみてください:
dumbsum(n::Integer) = n == 1 ? 1 : 1 + dumbsum(n-1)
dumbsum3() = dumbsum(3)dumbsum3をプロファイルしている場合、dumbsum(1)を実行中にバックトレースを取得すると、バックトレースは次のようになります:
dumbsum3
dumbsum(3)
dumbsum(2)
dumbsum(1)したがって、この子関数は3つのカウントを取得しますが、親は1つしか取得しません。この「ツリー」表現はこれをはるかに明確にし、この理由(他の理由の中でも)から、結果を表示する最も便利な方法であると思われます。
Accumulation and clearing
@profile の結果はバッファに蓄積されます。4d61726b646f776e2e436f64652822222c20224070726f66696c652229_40726566 の下で複数のコードを実行すると、Profile.print() で結合された結果が表示されます。これは非常に便利ですが、時には新たに始めたいこともあります。その場合は、Profile.clear() を使用できます。
Options for controlling the display of profile results
Profile.print には、これまで説明した以上のオプションがあります。完全な宣言を見てみましょう:
function print(io::IO = stdout, data = fetch(); kwargs...)まず、2つの位置引数について話し、その後にキーワード引数について説明します。
io– 結果をバッファ、例えばファイルに保存することができますが、デフォルトはstdout(コンソール)に出力されます。data– 分析したいデータを含みます。デフォルトではProfile.fetch()から取得され、事前に割り当てられたバッファからバックトレースを引き出します。たとえば、プロファイラをプロファイルしたい場合は、次のように言うことができます:data = copy(Profile.fetch()) Profile.clear() @profile Profile.print(stdout, data) # Prints the previous results Profile.print() # Prints results from Profile.print()
キーワード引数は、次の任意の組み合わせにすることができます:
format– 上述のように、バックトレースがツリー構造を示すインデント付き(デフォルト、:tree)で表示されるか、インデントなし(:flat)で表示されるかを決定します。C–trueの場合、C および Fortran コードからのバックトレースが表示されます(通常は除外されます)。Profile.print(C = true)を使って導入例を実行してみてください。これは、ボトルネックを引き起こしているのが Julia コードなのか C コードなのかを判断するのに非常に役立ちます。また、C = trueに設定すると、ネストの解釈が改善されますが、プロファイルダンプが長くなるという代償があります。combine– 一部のコード行には複数の操作が含まれています。たとえば、s += A[i]には配列参照 (A[i]) と加算操作が含まれています。これらは生成された機械コードの異なる行に対応しており、そのためこの行のバックトレース中に2つ以上の異なるアドレスがキャプチャされる可能性があります。combine = trueはそれらをまとめており、通常はこれが望ましいですが、combine = falseにすることで各ユニークな命令ポインタごとに別々の出力を生成することができます。maxdepth–:treeフォーマットでmaxdepthより深いフレームを制限します。sortedby–:flat形式での順序を制御します。:filefuncline(デフォルト)はソース行でソートし、:countは収集されたサンプルの数の順にソートします。noisefloor– サンプルのヒューリスティックノイズフロアよりも低いフレームを制限します(フォーマット:treeのみ適用)。これに試してみることをお勧めする値は 2.0 です(デフォルトは 0)。このパラメータは、n <= noisefloor * √Nの場合にサンプルを隠します。ここで、nはこの行のサンプル数、Nは呼び出し元のサンプル数です。mincount–mincount回数未満のフレームを制限します。
ファイル/関数名は時々切り詰められ(...で)、インデントは先頭に+nが付けられて切り詰められます。ここでnは、スペースが挿入されるはずだった追加のスペースの数です。深くネストされたコードの完全なプロファイルを取得したい場合、しばしば良いアイデアは、IOContextで広いdisplaysizeを使用してファイルに保存することです。
open("/tmp/prof.txt", "w") do s
Profile.print(IOContext(s, :displaysize => (24, 500)))
endConfiguration
@profile はバックトレースを蓄積するだけで、分析は Profile.print() を呼び出したときに行われます。長時間実行される計算の場合、バックトレースを保存するために事前に割り当てられたバッファが満杯になる可能性があります。その場合、バックトレースは停止しますが、計算は続行されます。その結果、重要なプロファイリングデータを見逃す可能性があります(その場合、警告が表示されます)。
関連するパラメータをこの方法で取得して構成できます:
Profile.init() # returns the current settings
Profile.init(n = 10^7, delay = 0.01)n は保存できる命令ポインタの総数で、デフォルト値は 10^6 です。通常のバックトレースが 20 の命令ポインタである場合、50000 のバックトレースを収集でき、これは統計的な不確実性が 1% 未満であることを示唆しています。これはほとんどのアプリケーションにとって十分かもしれません。
その結果、スナップショット間で要求された計算を実行するためにJuliaが得る時間を設定するdelay(秒単位)を変更する必要がある可能性が高くなります。非常に長時間実行されるジョブは、頻繁なバックトレースを必要としないかもしれません。デフォルト設定はdelay = 0.001です。もちろん、遅延を減らすことも増やすこともできますが、遅延がバックトレースを取得するのに必要な時間(著者のラップトップでは約30マイクロ秒)に似てくると、プロファイリングのオーバーヘッドが増加します。
Wall-time Profiler
Introduction & Problem Motivation
前のセクションで説明したプロファイラは、サンプリングCPUプロファイラです。高レベルでは、プロファイラは定期的にすべてのJulia計算スレッドを停止し、それらのバックトレースを収集し、その関数からのフレームを含むバックトレースサンプルの数に基づいて各関数に費やされた時間を推定します。ただし、プロファイラがスレッドを停止する直前にシステムスレッドで実行中のタスクのみがバックトレースを収集されることに注意してください。
このプロファイラは、通常、タスクの大部分が計算に依存するワークロードに適していますが、ほとんどのタスクがIO重視であるシステムや、コード内の同期プリミティブに関する競合を診断するにはあまり役立ちません。
このシンプルなワークロードを考えてみましょう:
using Base.Threads
using Profile
using PProf
ch = Channel(1)
const N_SPAWNED_TASKS = (1 << 10)
const WAIT_TIME_NS = 10_000_000
function spawn_a_bunch_of_tasks_waiting_on_channel()
for i in 1:N_SPAWNED_TASKS
Threads.@spawn begin
take!(ch)
end
end
end
function busywait()
t0 = time_ns()
while true
if time_ns() - t0 > WAIT_TIME_NS
break
end
end
end
function main()
spawn_a_bunch_of_tasks_waiting_on_channel()
for i in 1:N_SPAWNED_TASKS
put!(ch, i)
busywait()
end
end
Profile.@profile main()私たちの目標は、ch チャンネルに競合があるかどうかを検出することです。つまり、チャンネルで作業アイテムが生成される速度に対して、待機者の数が過剰であるかどうかを確認することです。
もしこれを実行すると、次の PProf フレームグラフが得られます:
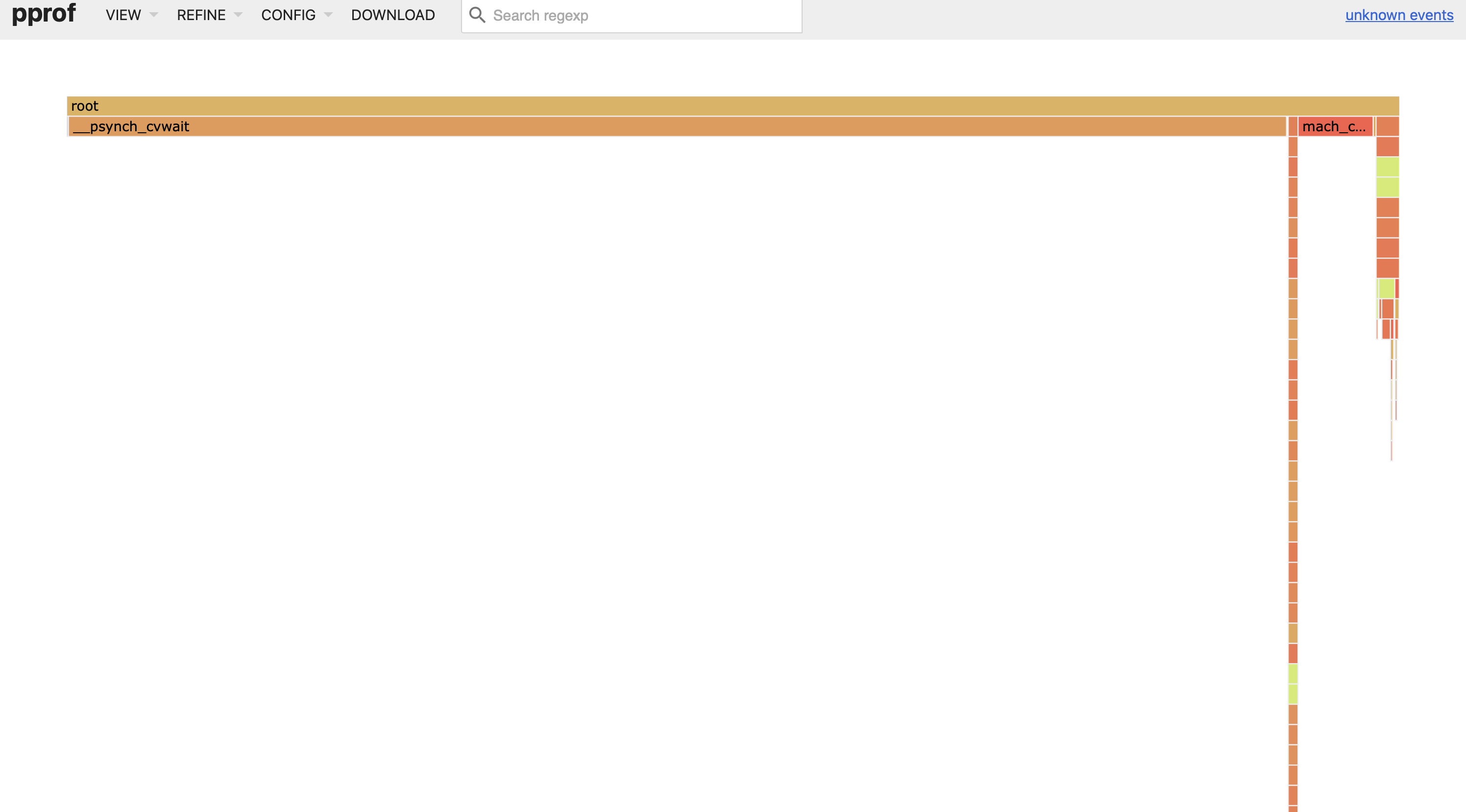
このプロファイルは、システムの同期プリミティブで競合が発生する場所を特定するのに役立つ情報を提供しません。チャネルの待機者はブロックされ、スケジュールから外されるため、システムスレッドはそれらの待機者に割り当てられたタスクを実行しなくなり、その結果、プロファイラによってサンプリングされることはありません。
Wall-time Profiler
スレッドをサンプリングする代わりに、したがって実行中のタスクのみをサンプリングするのではなく、ウォールタイムタスクプロファイラはタスクのスケジューリング状態に関係なくタスクを独立してサンプリングします。たとえば、プロファイラが実行中のときに同期プリミティブでスリープしているタスクは、プロファイラがバックトレースをキャプチャしようとしたときにアクティブに実行されていたタスクと同じ確率でサンプリングされます。
このアプローチにより、上記の例のように ch チャンネルでブロックされているタスクからのバックトレースが実際に表現されるプロファイルを構築することができます。
同じ例を実行しましょうが、今回はウォールタイムプロファイラーを使用します:
using Base.Threads
using Profile
using PProf
ch = Channel(1)
const N_SPAWNED_TASKS = (1 << 10)
const WAIT_TIME_NS = 10_000_000
function spawn_a_bunch_of_tasks_waiting_on_channel()
for i in 1:N_SPAWNED_TASKS
Threads.@spawn begin
take!(ch)
end
end
end
function busywait()
t0 = time_ns()
while true
if time_ns() - t0 > WAIT_TIME_NS
break
end
end
end
function main()
spawn_a_bunch_of_tasks_waiting_on_channel()
for i in 1:N_SPAWNED_TASKS
put!(ch, i)
busywait()
end
end
Profile.@profile_walltime main()次のフレームグラフを取得します:
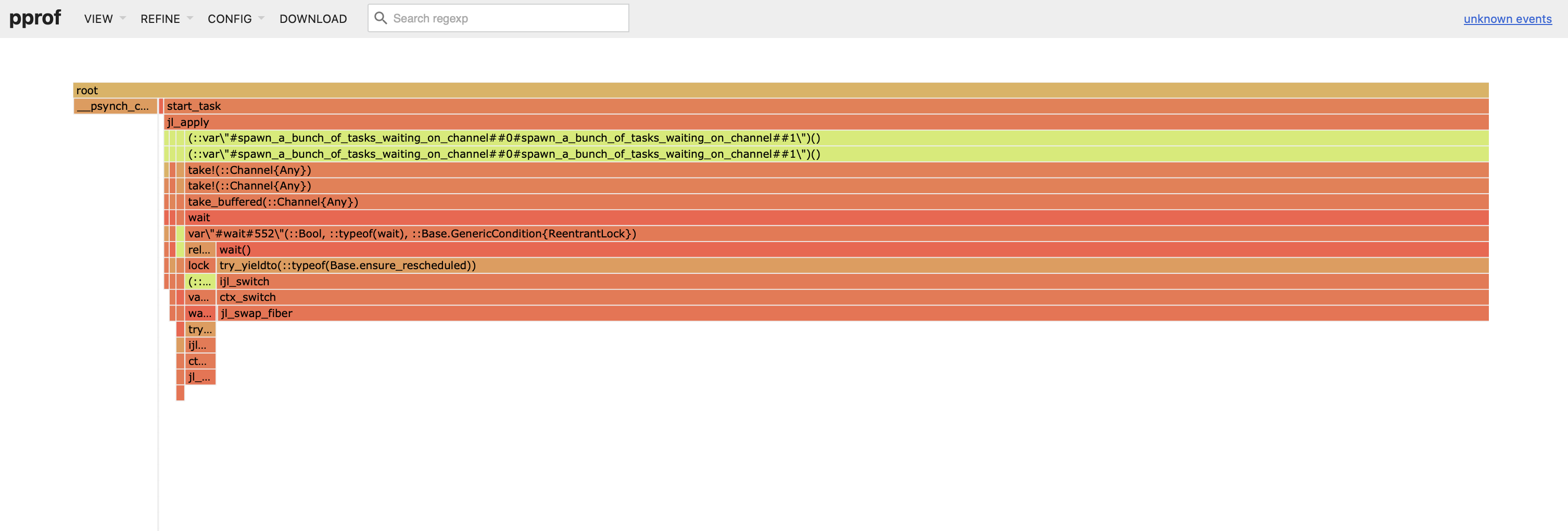
私たちは、多くのサンプルがチャネル関連の take! 関数から来ていることを確認しており、これにより ch に実際に過剰な数の待機者がいることを判断できます。
A Compute-Bound Workload
システム内のすべてのライブタスクをサンプリングするウォールタイムプロファイラーは、現在実行中のタスクだけでなく、パフォーマンスのホットスポットを特定するのに役立つ場合があります。たとえあなたのコードが計算に制約されていてもです。簡単な例を考えてみましょう:
using Base.Threads
using Profile
using PProf
ch = Channel(1)
const MAX_ITERS = (1 << 22)
const N_TASKS = (1 << 12)
function spawn_a_task_waiting_on_channel()
Threads.@spawn begin
take!(ch)
end
end
function sum_of_sqrt()
sum_of_sqrt = 0.0
for i in 1:MAX_ITERS
sum_of_sqrt += sqrt(i)
end
return sum_of_sqrt
end
function spawn_a_bunch_of_compute_heavy_tasks()
Threads.@sync begin
for i in 1:N_TASKS
Threads.@spawn begin
sum_of_sqrt()
end
end
end
end
function main()
spawn_a_task_waiting_on_channel()
spawn_a_bunch_of_compute_heavy_tasks()
end
Profile.@profile_walltime main()壁時間プロファイルを収集した後、次のフレームグラフが得られます:
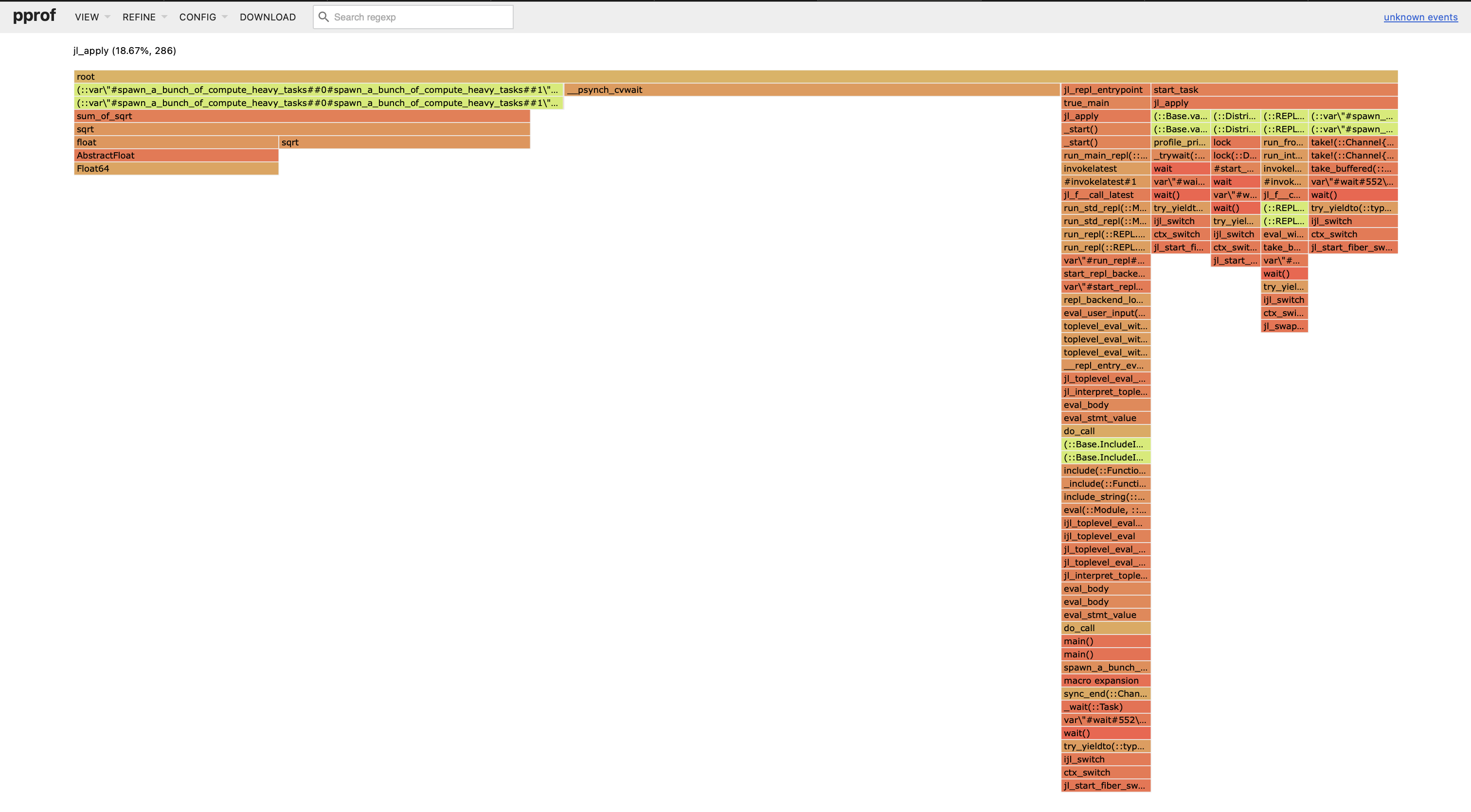
サンプルの中にsum_of_sqrtがどれだけ含まれているかに注意してください。これは私たちの例での高コスト計算関数です。
Identifying Task Sampling Failures in your Profile
現在の実装では、ウォールタイムプロファイラーは、最後のガーベジコレクション以降に生存しているタスクと、その後に作成されたタスクからサンプリングしようとします。しかし、ほとんどのタスクが非常に短命である場合、すでに完了したタスクをサンプリングしてしまい、バックトレースのキャプチャを逃す可能性があります。
failed_to_sample_task_fun または failed_to_stop_thread_fun を含むサンプルに遭遇した場合、これは短命のタスクが大量に発生していることを示しており、そのためバックトレースが収集できなかった可能性があります。
このシンプルな例を考えてみましょう:
using Base.Threads
using Profile
using PProf
const N_SPAWNED_TASKS = (1 << 16)
const WAIT_TIME_NS = 100_000
function spawn_a_bunch_of_short_lived_tasks()
for i in 1:N_SPAWNED_TASKS
Threads.@spawn begin
# Do nothing
end
end
end
function busywait()
t0 = time_ns()
while true
if time_ns() - t0 > WAIT_TIME_NS
break
end
end
end
function main()
GC.enable(false)
spawn_a_bunch_of_short_lived_tasks()
for i in 1:N_SPAWNED_TASKS
busywait()
end
GC.enable(true)
end
Profile.@profile_walltime main()spawn_a_bunch_of_short_lived_tasks で生成されるタスクは非常に短命であることに注意してください。これらのタスクはシステムの大部分を占めているため、サンプリングされたタスクのほとんどに対してバックトレースを取得することを見逃す可能性が高いです。
壁時間プロファイルを収集した後、次のフレームグラフを得ました:

failed_to_stop_thread_funからの大量のサンプルは、システム内に短命のタスクが多数存在することを確認しています。
Memory allocation analysis
パフォーマンスを向上させるための最も一般的な手法の一つは、メモリ割り当てを減らすことです。Juliaはこれを測定するためのいくつかのツールを提供しています:
@time
割り当ての合計量は、@time、@allocated、および @allocations を使用して測定できます。また、特定の行が割り当てを引き起こすことは、これらの行が引き起こすガーベジコレクションのコストを通じてプロファイリングから推測されることがよくあります。しかし、時には各コード行によって割り当てられるメモリの量を直接測定する方が効率的です。
GC Logging
@time は、式を評価する過程でのメモリ使用量とガベージコレクションに関する高レベルの統計をログに記録しますが、ガベージコレクションイベントごとにログを記録することも有用です。これにより、ガベージコレクタがどのくらいの頻度で実行されているか、毎回どのくらいの時間実行されているか、そして毎回どのくらいのゴミを収集しているかを直感的に把握できます。これは GC.enable_logging(true) を使用することで有効にでき、これによりJuliaはガベージコレクションが発生するたびにstderrにログを記録します。
Allocation Profiler
アロケーションプロファイラは、実行中に各アロケーションのスタックトレース、タイプ、およびサイズを記録します。Profile.Allocs.@profileで呼び出すことができます。
このアロケーションに関する情報は、Alloc オブジェクトの配列として返され、AllocResults オブジェクトにラップされています。これらを視覚化する最良の方法は、現在 PProf.jl および ProfileCanvas.jl パッケージを使用することで、最も多くのアロケーションを行っているコールスタックを視覚化できます。
アロケーションプロファイラーにはかなりのオーバーヘッドがあるため、いくつかのアロケーションをスキップすることで速度を上げるために sample_rate 引数を渡すことができます。 sample_rate=1.0 を渡すと、すべてを記録します(これは遅いです); sample_rate=0.1 を渡すと、アロケーションの10%のみを記録します(速い)、など。
古いバージョンのJuliaでは、すべてのケースで型をキャプチャできませんでした。古いバージョンのJuliaでは、Profile.Allocs.UnknownType型の割り当てが見られる場合、それはプロファイラがどの型のオブジェクトが割り当てられたのかを知らないことを意味します。これは主に、コンパイラによって生成されたコードからの割り当てが行われたときに発生しました。詳細については、issue #43688を参照してください。
Julia 1.11以降、すべてのアロケーションにはタイプが報告されるべきです。
このツールの使い方の詳細については、以下のJuliaCon 2022のトークをご覧ください: https://www.youtube.com/watch?v=BFvpwC8hEWQ
Allocation Profiler Example
この簡単な例では、PProfを使用してアロケーションプロファイルを視覚化します。代わりに別の視覚化ツールを使用することもできます。プロファイルを収集し(サンプルレートを指定)、それを視覚化します。
using Profile, PProf
Profile.Allocs.clear()
Profile.Allocs.@profile sample_rate=0.0001 my_function()
PProf.Allocs.pprof()ここでは、サンプルレートを調整する方法についてのより詳細な例を示します。目指すべき良いサンプル数は約1,000〜10,000です。多すぎると、プロファイルビジュアライザーが圧倒され、プロファイリングが遅くなります。少なすぎると、代表的なサンプルが得られません。
julia> import Profile
julia> @time my_function() # Estimate allocations from a (second-run) of the function
0.110018 seconds (1.50 M allocations: 58.725 MiB, 17.17% gc time)
500000
julia> Profile.Allocs.clear()
julia> Profile.Allocs.@profile sample_rate=0.001 begin # 1.5 M * 0.001 = ~1.5K allocs.
my_function()
end
500000
julia> prof = Profile.Allocs.fetch(); # If you want, you can also manually inspect the results.
julia> length(prof.allocs) # Confirm we have expected number of allocations.
1515
julia> using PProf # Now, visualize with an external tool, like PProf or ProfileCanvas.
julia> PProf.Allocs.pprof(prof; from_c=false) # You can optionally pass in a previously fetched profile result.
Analyzing 1515 allocation samples... 100%|████████████████████████████████| Time: 0:00:00
Main binary filename not available.
Serving web UI on http://localhost:62261
"alloc-profile.pb.gz"その後、http://localhost:62261 に移動することでプロファイルを表示でき、プロファイルはディスクに保存されます。詳細なオプションについては PProf パッケージを参照してください。
Allocation Profiling Tips
上記の通り、プロフィールには約1,000〜10,000のサンプルを目指してください。
すべての割り当ての空間で均一にサンプリングしており、割り当てのサイズによってサンプルに重みを付けていないことに注意してください。したがって、特定の割り当てプロファイルは、sample_rate=1を設定していない限り、プログラム内で最も多くのバイトが割り当てられている場所の代表的なプロファイルを提供しない可能性があります。
アロケーションは、ユーザーが直接オブジェクトを構築することから来る場合もありますが、ランタイム内部から来たり、型の不安定性を処理するためにコンパイルされたコードに挿入されることもあります。「ソースコード」ビューを見ることは、それらを特定するのに役立ちます。そして、Cthulhu.jlのような他の外部ツールは、アロケーションの原因を特定するのに役立ちます。
Allocation Profile Visualization Tools
現在、すべてのアロケーションプロファイルを表示できるいくつかのプロファイリング可視化ツールがあります。以下は、私たちが知っている主要なツールの小さなリストです:
VSCodeの組み込みプロファイルビジュアライザー(
@profview_allocs) [docs needed]REPLで結果を直接表示する
- 結果は、
Profile.Allocs.fetch()を介してREPLで確認できます。これにより、スタックトレースと各アロケーションのタイプを表示できます。
- 結果は、
Line-by-Line Allocation Tracking
代替的な割り当ての測定方法は、--track-allocation=<setting> コマンドラインオプションを使用して Julia を起動することです。このオプションでは、none(デフォルト、割り当てを測定しない)、user(Julia のコアコードを除くすべての場所でメモリ割り当てを測定)、または all(各行の Julia コードでメモリ割り当てを測定)を選択できます。割り当ては、コンパイルされたコードの各行について測定されます。Julia を終了すると、累積結果がファイル名の後に .mem が付加されたテキストファイルに書き込まれ、ソースファイルと同じディレクトリに保存されます。各行には、割り当てられたバイトの合計数がリストされます。Coverage package には、割り当てられたバイト数の順に行をソートするなどの基本的な分析ツールが含まれています。
結果を解釈する際には、いくつかの重要な詳細があります。user設定の下では、REPLから直接呼び出された関数の最初の行は、REPLコード自体で発生するイベントによる割り当てを示します。さらに重要なことに、JITコンパイルも割り当てカウントに加わります。なぜなら、Juliaのコンパイラの多くはJuliaで書かれており(コンパイルには通常メモリの割り当てが必要です)、そのためです。推奨される手順は、分析したいすべてのコマンドを実行してコンパイルを強制し、その後Profile.clear_malloc_data()を呼び出してすべての割り当てカウンタをリセットすることです。最後に、目的のコマンドを実行し、Juliaを終了して.memファイルの生成をトリガーします。
--track-allocation はコード生成を変更してアロケーションをログに記録します。そのため、オプションなしで発生するアロケーションとは異なる場合があります。代わりに allocation profiler の使用をお勧めします。
External Profiling
現在、Juliaは外部プロファイリングツールとしてIntel VTune、OProfile、およびperfをサポートしています。
選択したツールに応じて、Make.user で USE_INTEL_JITEVENTS、USE_OPROFILE_JITEVENTS、および USE_PERF_JITEVENTS を 1 に設定してコンパイルします。複数のフラグがサポートされています。
Juliaを実行する前に、環境変数 ENABLE_JITPROFILING を1に設定してください。
今、あなたはそれらのツールを使うための多くの方法を持っています!例えば、OProfileを使ってシンプルな記録を試すことができます:
>ENABLE_JITPROFILING=1 sudo operf -Vdebug ./julia test/fastmath.jl
>opreport -l `which ./julia`または perf を使って同様に:
$ ENABLE_JITPROFILING=1 perf record -o /tmp/perf.data --call-graph dwarf -k 1 ./julia /test/fastmath.jl
$ perf inject --jit --input /tmp/perf.data --output /tmp/perf-jit.data
$ perf report --call-graph -G -i /tmp/perf-jit.dataあなたのプログラムについて測定できる興味深いことはまだまだたくさんあります。包括的なリストを得るには、Linux perf examples pageをお読みください。
実行ごとに perf.data ファイルが保存されることを忘れないでください。このファイルは、小さなプログラムでもかなり大きくなる可能性があります。また、perf LLVM モジュールは一時的にデバッグオブジェクトを ~/.debug/jit に保存しますので、そのフォルダーを頻繁にクリーンアップすることを忘れないでください。