Inference
How inference works
줄리아 컴파일러에서 "타입 추론"은 입력 값의 타입으로부터 이후 값의 타입을 유추하는 과정을 의미합니다. 줄리아의 추론 접근 방식은 아래 블로그 게시물에서 설명되었습니다:
- Shows a simplified implementation of the data-flow analysis algorithm, that Julia's type inference routine is based on.
- Gives a high level view of inference with a focus on its inter-procedural convergence guarantee.
- Explains a refinement on the algorithm introduced in 2.
Debugging compiler.jl
Julia 세션을 시작하고 compiler/*.jl을 편집한 다음(예: print 문을 삽입하기 위해) 실행 중인 세션에서 Core.Compiler를 교체하려면 base로 이동하여 include("compiler/compiler.jl")를 실행하면 됩니다. 이 트릭은 각 변경 사항에 대해 Julia를 다시 빌드하는 것보다 훨씬 빠른 개발로 이어집니다.
대신, Revise.jl 패키지를 사용하여 Revise.track(Core.Compiler) 명령어로 Julia 세션의 시작 부분에서 컴파일러 변경 사항을 추적할 수 있습니다. Revise documentation에서 설명한 바와 같이, 수정된 파일이 저장되면 컴파일러에 대한 수정 사항이 반영됩니다.
편리한 추론 진입점은 typeinf_code입니다. 다음은 convert(Int, UInt(1))에 대한 추론을 실행하는 데모입니다:
# Get the method
atypes = Tuple{Type{Int}, UInt} # argument types
mths = methods(convert, atypes) # worth checking that there is only one
m = first(mths)
# Create variables needed to call `typeinf_code`
interp = Core.Compiler.NativeInterpreter()
sparams = Core.svec() # this particular method doesn't have type-parameters
run_optimizer = true # run all inference optimizations
types = Tuple{typeof(convert), atypes.parameters...} # Tuple{typeof(convert), Type{Int}, UInt}
Core.Compiler.typeinf_code(interp, m, types, sparams, run_optimizer)디버깅 모험에서 MethodInstance가 필요하다면, 위의 여러 변수를 사용하여 Core.Compiler.specialize_method를 호출하여 찾아볼 수 있습니다. CodeInfo 객체는 다음과 같이 얻을 수 있습니다.
# Returns the CodeInfo object for `convert(Int, ::UInt)`:
ci = (@code_typed convert(Int, UInt(1)))[1]The inlining algorithm (inline_worthy)
인라인 작업의 대부분은 ssa_inlining_pass!에서 수행됩니다. 그러나 "내 함수가 왜 인라인되지 않았나요?"라는 질문을 한다면, 함수 호출을 인라인할지 말지를 결정하는 inline_worthy에 관심이 있을 것입니다.
inline_worthy는 "저렴한" 함수가 인라인 처리되는 비용 모델을 구현합니다. 더 구체적으로, 예상 실행 시간이 인라인 처리되지 않았을 경우 issue a call하는 데 걸리는 시간에 비해 크지 않은 경우 함수를 인라인 처리합니다. 이 비용 모델은 매우 간단하며 많은 중요한 세부 사항을 무시합니다. 예를 들어, 모든 for 루프는 한 번만 실행될 것처럼 분석되며, if...else...end의 비용은 모든 분기의 합산 비용을 포함합니다. 현재 비용 모델이 실제 실행 시간 비용을 얼마나 잘 예측하는지 테스트할 수 있는 함수 모음이 부족하다는 점도 인정할 가치가 있습니다. 그러나 BaseBenchmarks는 인라인 알고리즘의 수정에 대한 성공과 실패에 대한 간접적인 정보를 많이 제공합니다.
비용 모델의 기초는 add_tfunc 및 그 호출자에서 구현된 조회 테이블로, Julia의 내장 함수 각각에 CPU 사이클로 측정된 추정 비용을 할당합니다. 이러한 비용은 standard ranges for common architectures를 기반으로 하며 (자세한 내용은 Agner Fog's analysis를 참조하십시오).
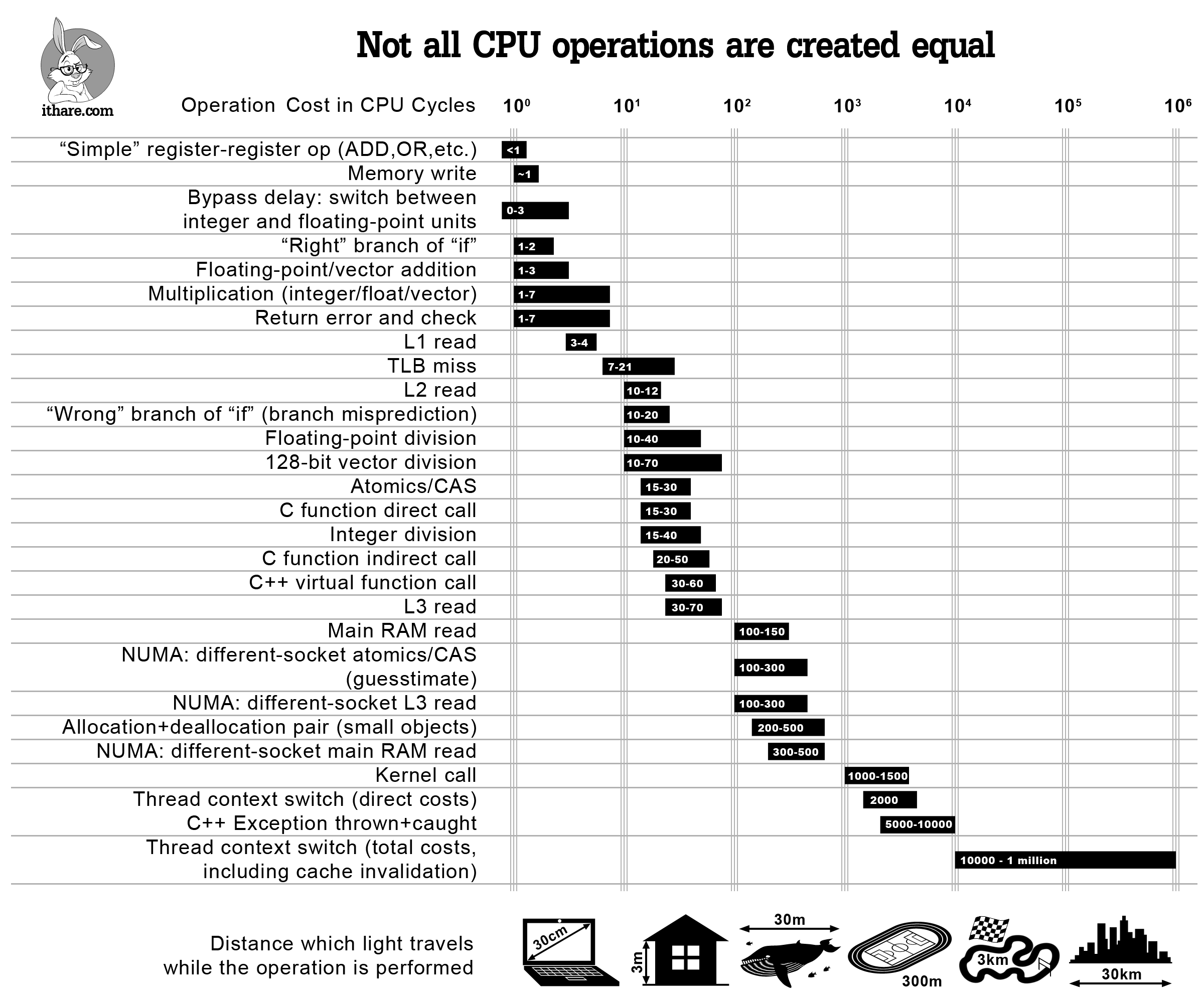{kind=link}
우리는 이 저수준 조회 테이블을 여러 특별한 경우로 보완합니다. 예를 들어, 모든 입력 및 출력 유형이 미리 추론된 :invoke 표현식은 고정 비용(현재 20 사이클)이 할당됩니다. 반면, 내장 함수가 아닌 함수에 대한 :call 표현식은 호출이 동적 디스패치를 필요로 함을 나타내며, 이 경우 Params.inline_nonleaf_penalty에 의해 설정된 비용(현재 1000으로 설정됨)을 할당합니다. 이는 동적 디스패치의 원시 비용에 대한 "기본 원칙" 추정이 아니라, 동적 디스패치가 매우 비쌉니다라는 단순한 휴리스틱임을 유의하십시오.
각 문장은 statement_cost라는 함수에서 총 비용을 분석합니다. 각 문장과 관련된 비용은 다음과 같이 표시할 수 있습니다:
julia> Base.print_statement_costs(stdout, map, (typeof(sqrt), Tuple{Int},)) # map(sqrt, (2,))
map(f, t::Tuple{Any}) @ Base tuple.jl:281
0 1 ─ %1 = $(Expr(:boundscheck, true))::Bool
0 │ %2 = Base.getfield(_3, 1, %1)::Int64
1 │ %3 = Base.sitofp(Float64, %2)::Float64
0 │ %4 = Base.lt_float(%3, 0.0)::Bool
0 └── goto #3 if not %4
0 2 ─ invoke Base.Math.throw_complex_domainerror(:sqrt::Symbol, %3::Float64)::Union{}
0 └── unreachable
20 3 ─ %8 = Base.Math.sqrt_llvm(%3)::Float64
0 └── goto #4
0 4 ─ goto #5
0 5 ─ %11 = Core.tuple(%8)::Tuple{Float64}
0 └── return %11
라인 비용은 왼쪽 열에 있습니다. 여기에는 인라인화 및 기타 최적화 형태의 결과가 포함됩니다.