JIT Design and Implementation
이 문서는 코드 생성이 완료되고 최적화되지 않은 LLVM IR이 생성된 후 Julia의 JIT 설계 및 구현에 대해 설명합니다. JIT는 이 IR을 기계 코드로 최적화하고 컴파일하며, 이를 현재 프로세스에 링크하고 실행 가능하도록 코드를 만드는 역할을 합니다.
Introduction
JIT는 컴파일 리소스를 관리하고, 이전에 컴파일된 코드를 조회하며, 새로운 코드를 컴파일하는 역할을 합니다. 주로 LLVM의 On-Request-Compilation (ORCv2) 기술을 기반으로 구축되어 있으며, 이는 동시 컴파일, 지연 컴파일 및 별도의 프로세스에서 코드를 컴파일할 수 있는 기능과 같은 여러 유용한 기능을 지원합니다. LLVM은 LLJIT 형태로 기본 JIT 컴파일러를 제공하지만, Julia는 많은 ORCv2 API를 직접 사용하여 자체 맞춤형 JIT 컴파일러를 생성합니다.
Overview
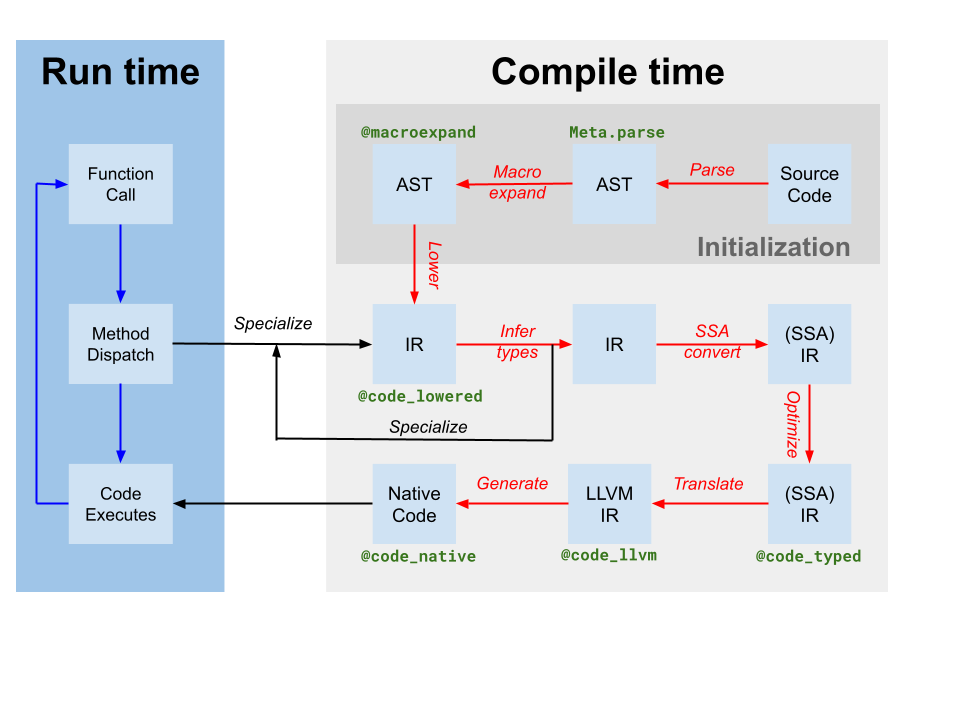
Codegen은 원래의 Julia SSA IR에서 하나 이상의 Julia 함수에 대한 IR을 포함하는 LLVM 모듈을 생성합니다(위의 컴파일러 다이어그램에서 translate로 표시됨). 또한 코드 인스턴스와 LLVM 함수 이름 간의 매핑을 생성합니다. 그러나 Julia 기반 컴파일러가 Julia IR에 대해 일부 최적화를 적용했음에도 불구하고, Codegen이 생성한 LLVM IR은 여전히 많은 최적화 기회를 포함하고 있습니다. 따라서 JIT가 수행하는 첫 번째 단계는 LLVM 모듈에서 타겟 독립적인 최적화 파이프라인[tdp]을 실행하는 것입니다. 그런 다음 JIT는 타겟 종속 최적화 파이프라인을 실행하며, 여기에는 타겟 특정 최적화 및 코드 생성이 포함되고, 객체 파일을 출력합니다. 마지막으로 JIT는 생성된 객체 파일을 현재 프로세스에 링크하고 코드를 실행 가능하게 만듭니다. 이 모든 것은 src/jitlayers.cpp의 코드에 의해 제어됩니다.
현재, 하나의 링크 프로그램(RuntimeDyld)에서 부과한 제한으로 인해 최적화-컴파일-링크 파이프라인에 한 번에 하나의 스레드만 들어갈 수 있습니다. 그러나 JIT는 동시 최적화 및 컴파일을 지원하도록 설계되었으며, RuntimeDyld가 모든 플랫폼에서 완전히 대체되면 링크 제한이 해제될 것으로 예상됩니다.
Optimization Pipeline
최적화 파이프라인은 LLVM의 새로운 패스 매니저를 기반으로 하지만, 파이프라인은 Julia의 필요에 맞게 사용자 정의되었습니다. 파이프라인은 src/pipeline.cpp에 정의되어 있으며, 아래에 자세히 설명된 여러 단계를 통해 진행됩니다.
- 조기 단순화
- 이러한 패스는 주로 IR을 단순화하고 패턴을 정규화하여 이후 패스가 이러한 패턴을 더 쉽게 식별할 수 있도록 하는 데 사용됩니다. 또한 분기 예측 힌트 및 주석과 같은 다양한 내재적 호출은 다른 메타데이터 또는 다른 IR 기능으로 낮춰집니다.
SimplifyCFG(제어 흐름 그래프 단순화),DCE(죽은 코드 제거), 및SROA(집합체의 스칼라 대체)는 여기서 주요 역할을 하는 몇 가지입니다.
- 이러한 패스는 주로 IR을 단순화하고 패턴을 정규화하여 이후 패스가 이러한 패턴을 더 쉽게 식별할 수 있도록 하는 데 사용됩니다. 또한 분기 예측 힌트 및 주석과 같은 다양한 내재적 호출은 다른 메타데이터 또는 다른 IR 기능으로 낮춰집니다.
- 조기 최적화
- 이러한 패스는 일반적으로 저렴하며 IR의 명령어 수를 줄이고 다른 명령어에 지식을 전파하는 데 주로 집중합니다. 예를 들어,
EarlyCSE은 공통 부분 표현 제거를 수행하는 데 사용되며,InstCombine및InstSimplify는 연산을 덜 비싸게 만들기 위해 여러 가지 작은 피프홀 최적화를 수행합니다.
- 이러한 패스는 일반적으로 저렴하며 IR의 명령어 수를 줄이고 다른 명령어에 지식을 전파하는 데 주로 집중합니다. 예를 들어,
- 루프 최적화
- 이러한 패스는 루프를 정규화하고 단순화합니다. 루프는 종종 핫 코드이므로 루프 최적화는 성능에 매우 중요합니다. 여기에는
LoopRotate,LICM, 및LoopFullUnroll가 포함됩니다. 특정 경계가 초과되지 않음을 증명할 수 있는IRCE패스의 결과로 일부 경계 검사 제거도 발생합니다.
- 이러한 패스는 루프를 정규화하고 단순화합니다. 루프는 종종 핫 코드이므로 루프 최적화는 성능에 매우 중요합니다. 여기에는
- 스칼라 최적화
- 벡터화
- Automatic vectorization은 CPU 집약적인 코드에 대한 매우 강력한 변환입니다. 간단히 말해, 벡터화는 single instruction on multiple data (SIMD)을 실행할 수 있게 해주며, 예를 들어 8개의 덧셈 연산을 동시에 수행할 수 있습니다. 그러나 코드가 벡터화가 가능하고 벡터화하는 것이 이익이 되도록 증명하는 것은 어렵고, 이는 벡터화가 가치가 있는 상태로 IR을 조정하기 위해 이전 최적화 패스에 크게 의존합니다.
- 내재적 하강
- 줄리아는 객체 할당, 가비지 컬렉션 및 예외 처리를 위한 이유로 여러 사용자 정의 내장 함수를 삽입합니다. 이러한 내장 함수는 원래 최적화 기회를 더 명확하게 만들기 위해 배치되었지만, 이제는 IR이 기계 코드로 생성될 수 있도록 LLVM IR로 낮춰집니다.
- 정리
- 이러한 패스는 마지막 기회 최적화이며, 융합 곱셈-덧셈 전파 및 나눗셈-나머지 단순화와 같은 작은 최적화를 수행합니다. 또한, 반정밀 부동 소수점 숫자를 지원하지 않는 타겟은 여기에서 반정밀 명령어를 단정밀 명령어로 낮추고, 샌디타이저 지원을 제공하기 위해 패스가 추가됩니다.
Target-Dependent Optimization and Code Generation
LLVM은 특정 플랫폼에 대한 TargetMachine에 위치한 동일한 파이프라인에서 타겟 의존 최적화 및 기계 코드 생성을 제공합니다. 이러한 패스에는 명령어 선택, 명령어 스케줄링, 레지스터 할당 및 기계 코드 방출이 포함됩니다. LLVM 문서는 이 프로세스에 대한 좋은 개요를 제공하며, LLVM 소스 코드는 파이프라인 및 패스에 대한 세부 정보를 찾기에 가장 좋은 장소입니다.
Linking
현재 Julia는 구형 RuntimeDyld 링커와 신형 JITLink 링커 사이에서 전환 중입니다. JITLink는 RuntimeDyld가 지원하지 않는 여러 기능을 포함하고 있으며, 예를 들어 동시 및 재진입 링크를 지원하지만, 현재 프로파일링 통합에 대한 좋은 지원이 부족하고 RuntimeDyld가 지원하는 모든 플랫폼을 아직 지원하지 않습니다. 시간이 지나면서 JITLink는 RuntimeDyld를 완전히 대체할 것으로 예상됩니다. JITLink에 대한 추가 세부정보는 LLVM 문서에서 확인할 수 있습니다.
Execution
코드가 현재 프로세스에 연결되면 실행할 수 있게 됩니다. 이 사실은 invoke, specsigflags, 및 specptr 필드를 적절하게 업데이트하여 생성 코드 인스턴스에 알려집니다. 코드 인스턴스는 invoke, specsigflags, 및 specptr 필드를 업그레이드하는 것을 지원하며, 이는 특정 시점에 존재하는 이러한 필드의 모든 조합이 호출될 수 있는 유효한 상태여야 함을 의미합니다. 이를 통해 JIT는 기존 코드 인스턴스를 무효화하지 않고 이러한 필드를 업데이트할 수 있으며, 잠재적인 미래의 동시 JIT를 지원합니다. 구체적으로, 다음 상태가 유효할 수 있습니다:
invoke는 NULL이고,specsigflags는 0b00이며,specptr는 NULL입니다.- 이것은 코드 인스턴스의 초기 상태이며, 코드 인스턴스가 아직 컴파일되지 않았음을 나타냅니다.
invoke는 null이 아니고,specsigflags는 0b00이며,specptr는 NULL입니다.- 이것은 코드 인스턴스가 어떤 특수화도 없이 컴파일되지 않았음을 나타내며, 코드 인스턴스는 직접 호출되어야 함을 의미합니다. 이 경우
invoke는specsigflags나specptr필드를 읽지 않으므로, 이 필드들은invoke포인터를 무효화하지 않고 수정될 수 있습니다.
- 이것은 코드 인스턴스가 어떤 특수화도 없이 컴파일되지 않았음을 나타내며, 코드 인스턴스는 직접 호출되어야 함을 의미합니다. 이 경우
invoke는 null이 아니고,specsigflags는 0b10이며,specptr는 null이 아닙니다.- 이것은 코드 인스턴스가 컴파일되었지만, 코드 생성에 의해 특수화된 함수 시그니처가 불필요하다고 판단되었음을 나타냅니다.
invoke는 null이 아니고,specsigflags는 0b11이며,specptr는 null이 아닙니다.- 이것은 코드 인스턴스가 컴파일되었고, 코드 생성에 의해 특수화된 함수 시그니처가 필요하다고 판단되었음을 나타냅니다.
specptr필드는 특수화된 함수 시그니처에 대한 포인터를 포함합니다.invoke포인터는specsigflags와specptr필드를 모두 읽는 것이 허용됩니다.
- 이것은 코드 인스턴스가 컴파일되었고, 코드 생성에 의해 특수화된 함수 시그니처가 필요하다고 판단되었음을 나타냅니다.
또한 업데이트 과정에서 발생하는 여러 가지 전이 상태가 있습니다. 이러한 잠재적인 상황을 고려하기 위해, 이 코드인스트 필드를 다룰 때 다음의 쓰기 및 읽기 패턴을 사용해야 합니다.
invoke,specsigflags, 및specptr를 작성할 때:- NULL 값을 가정하여 specptr에 대한 원자적 비교-교환 작업을 수행합니다. 이 비교-교환 작업은 최소한의 획득-해제 순서를 가져야 하며, 이는 쓰기에서 나머지 메모리 작업의 순서 보장을 제공합니다.
specptr가 null이 아니면, 쓰기 작업을 중단하고specsigflags의 비트 0b10이 기록될 때까지 기다립니다.specsigflags의 새로운 최하위 비트를 최종 값으로 작성하십시오. 이는 완화된 쓰기일 수 있습니다.invoke포인터를 최종 값으로 설정합니다. 이는invoke의 읽기와 동기화하기 위해 최소한의 release 메모리 순서를 가져야 합니다.specsigflags의 두 번째 비트를 1로 설정합니다. 이는specsigflags의 읽기와 동기화하기 위해 최소한 릴리스 메모리 순서를 가져야 합니다. 이 단계는 쓰기 작업을 완료하고 모든 다른 스레드에 모든 필드가 설정되었음을 알립니다.
invoke,specsigflags, 및specptr를 모두 읽을 때:invoke필드를 최소한의 획득 메모리 순서로 읽습니다. 이 로드는initial_invoke라고 합니다.initial_invoke가 NULL인 경우, codeinst는 아직 실행 가능하지 않습니다.invoke는 NULL이며,specsigflags는 0b00으로 처리될 수 있고,specptr는 NULL로 처리될 수 있습니다.specptr필드를 최소한의 획득 메모리 순서로 읽습니다.- 만약
specptr가 NULL이라면,initial_invoke포인터는 올바른 실행을 보장하기 위해specptr에 의존해서는 안 됩니다. 따라서,invoke는 NULL이 아니며,specsigflags는 0b00으로 처리될 수 있고,specptr는 NULL로 처리될 수 있습니다. specptr가 null이 아니면,initial_invoke는specptr를 사용하는 최종invoke필드가 아닐 수 있습니다. 이는specptr가 기록되었지만invoke가 아직 기록되지 않은 경우에 발생할 수 있습니다. 따라서specsigflags의 두 번째 비트가 1로 설정될 때까지 최소한 acquire 메모리 순서를 사용하여 대기하십시오.invoke필드를 최소한의 획득 메모리 순서로 다시 읽습니다. 이 로드는final_invoke라고 합니다.specsigflags필드를 임의의 메모리 순서로 읽습니다.invoke는final_invoke이고,specsigflags는 7단계에서 읽은 값이며,specptr는 3단계에서 읽은 값입니다.
specptr를 다른 그러나 동등한 함수 포인터로 업데이트할 때:- 새 함수 포인터를
specptr에 릴리스 저장하십시오. 여기서의 경쟁 조건은 무해해야 하며, 이전 함수 포인터는 여전히 유효해야 하고, 새로운 포인터도 유효해야 합니다.specptr에 포인터가 기록된 후에는 나중에 덮어쓰여지더라도 항상 호출 가능해야 합니다.
- 새 함수 포인터를
이러한 쓰기, 읽기 및 업데이트 단계는 복잡하지만, JIT가 기존 코드 인스턴스를 무효화하지 않고 코드 인스턴스를 업데이트할 수 있도록 보장하며, JIT가 기존 invoke 포인터를 무효화하지 않고 코드 인스턴스를 업데이트할 수 있도록 합니다. 이는 JIT가 미래에 더 높은 최적화 수준에서 함수를 재최적화할 수 있는 가능성을 제공하며, 또한 JIT가 미래에 함수의 동시 컴파일을 지원할 수 있도록 합니다.
- tdpThis is not a totally-target independent pipeline, as transformations such as vectorization rely upon target information such as vector register width and cost modeling. Additionally, codegen itself makes a few target-dependent assumptions, and the optimization pipeline will take advantage of that knowledge.