Garbage Collection in Julia
Introduction
Julia имеет неподвижный, частично конкурентный, параллельный, генерационный и в основном точный сборщик мусора с пометкой и очисткой (интерфейс для консервативного сканирования стека предоставляется в качестве опции для пользователей, которые хотят вызывать Julia из C).
Allocation
Джулия использует два типа аллокаторов, размер запроса на выделение памяти определяет, какой из них будет использован. Объекты размером до 2k байт выделяются из пула аллокаторов с свободным списком на поток, в то время как объекты размером более 2k байт выделяются через libc malloc.
Пул-аллокатор Julia разбивает объекты на разные классы размеров, так что страница памяти, управляемая пул-аллокатором (которая охватывает 4 страницы операционной системы на платформах с 64-битной архитектурой), содержит только объекты одного и того же класса размера. Каждая страница памяти от пул-аллокатора связана с некоторыми метаданными страницы, хранящимися в списках без блокировок на уровне каждого потока. Метаданные страницы содержат информацию, такую как наличие живых объектов на странице, количество свободных слотов и смещения до первых и последних объектов в списке свободных объектов, содержащемся на этой странице. Эти метаданные используются для оптимизации фазы сборки: страница, на которой нет живых объектов, может быть возвращена операционной системе без необходимости ее сканирования, например.
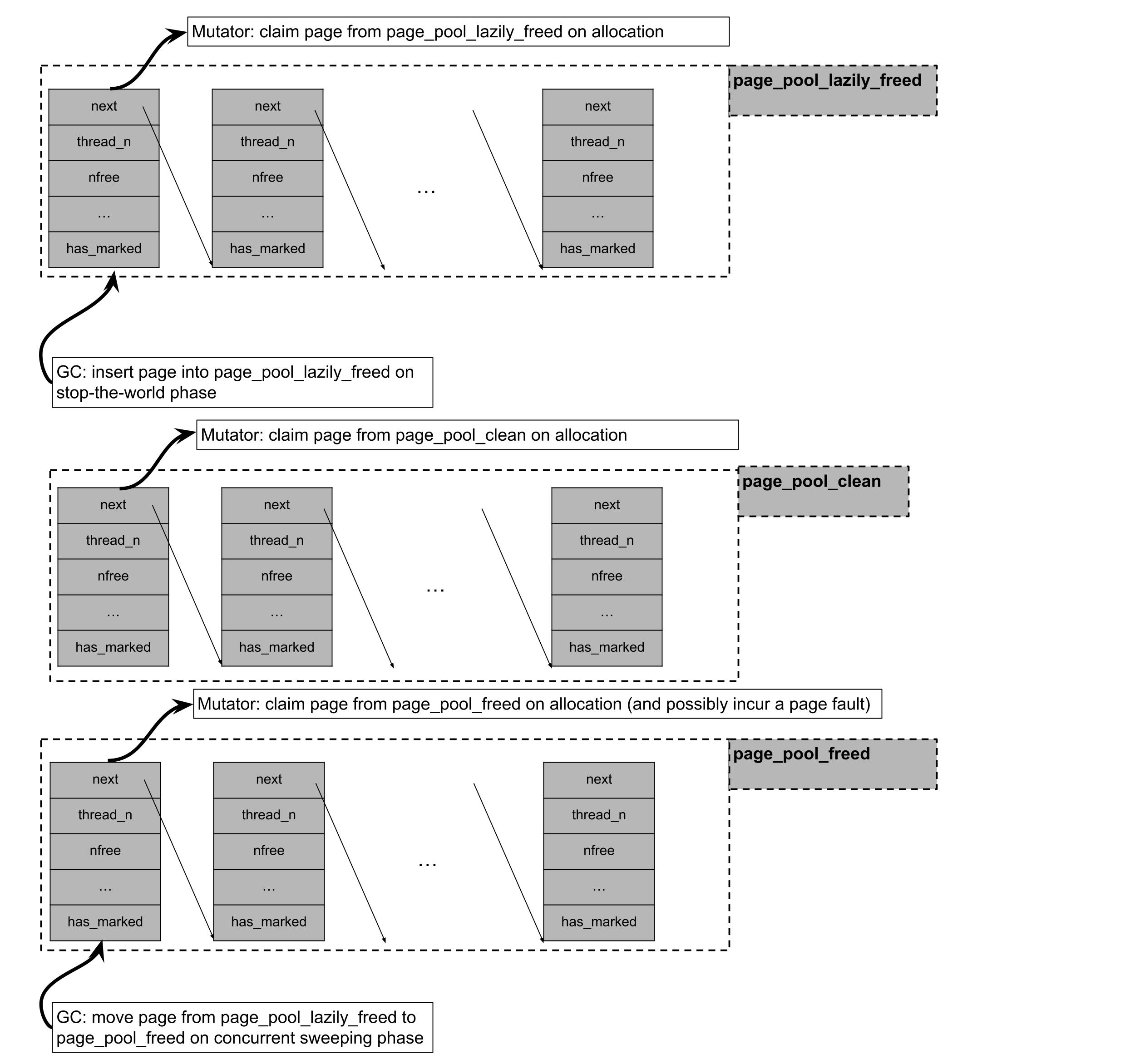
Хотя страница, не содержащая объектов, может быть возвращена операционной системе, ее связанная метаинформация навсегда выделена и может пережить данную страницу. Как упоминалось выше, метаинформация для выделенных страниц хранится в списках без блокировок на уровне потоков. Метаинформация для свободных страниц, однако, может храниться в трех отдельных списках без блокировок в зависимости от того, была ли страница отображена, но никогда не использовалась (page_pool_clean), или была ли страница лениво очищена и ждет, чтобы ее обработал фоновый поток сборщика мусора (page_pool_lazily_freed), или была ли страница обработана (page_pool_freed).
Пул-аллокатор Julia следует дисциплине "уровневого" распределения. При запросе страницы памяти для пул-аллокатора Julia будет:
- Попробуйте запросить страницу из
page_pool_lazily_freed, которая содержит страницы, которые были пустыми на последней фазе остановки мира, но еще не были обработаны параллельным потоком сборщика мусора. - Если не удалось получить страницу из
page_pool_lazily_freed, она попытается получить страницу изthe page_pool_clean, который содержит страницы, которые были mmaped при предыдущем запросе на выделение страницы, но никогда не были доступны. - Если не удалось получить страницу из
pool_page_cleanи изpage_pool_lazily_freed, она попытается получить страницу изpage_pool_freed, который содержит страницы, которые уже были обработаны параллельным потоком сборщика мусора и чей базовый виртуальный адрес может быть переработан. - Если он не удался во всех вышеупомянутых попытках, он выделит пакет страниц, заберет одну страницу для себя и вставит оставшиеся страницы в
page_pool_clean.
Marking and Generational Collection
Фаза маркировки в Julia реализована через параллельный итеративный поиск в глубину по графу объектов. Сборщик Julia не перемещает объекты, поэтому информация о возрасте объекта не может быть определена только по области памяти, в которой находится объект, но должна быть как-то закодирована в заголовке объекта или в отдельной таблице. Два младших бита заголовка объекта используются для хранения, соответственно, бита маркировки, который устанавливается, когда объект сканируется в ходе фазы маркировки, и бита возраста для генерационной сборки.
Генерационная сборка реализована через липкие биты: объекты помещаются в стек меток и, следовательно, отслеживаются, только если их метки не установлены. Когда объекты достигают старшего поколения, их метки не сбрасываются во время так называемого "быстрого обхода", что приводит к тому, что эти объекты не отслеживаются в последующей фазе маркировки. Однако "полный обход" приводит к сбросу меток всех объектов, что приводит к тому, что все объекты отслеживаются в последующей фазе маркировки. Объекты повышаются до следующего поколения во время каждой фазы обхода, которую они переживают. На стороне мутатора записи полей перехватываются через барьер записи, который помещает адрес объекта в набор запомненных объектов для каждого потока, если объект находится в последнем поколении, и если объект в поле, в которое производится запись, не является таковым. Объекты в этом запомненном наборе затем отслеживаются во время фазы маркировки.
Sweeping
Сбор объектов из пулов для Julia может быть разделен на две категории: если данная страница, управляемая аллокатором пула, содержит хотя бы один живой объект, то свободный список должен быть проложен через его мертвые объекты; если данная страница не содержит живых объектов, то ее физическая память может быть возвращена операционной системе, например, с помощью системных вызовов madvise в Linux.
Первая категория очистки параллелизована через кражу работы. Для второй категории очистки, если включена параллельная очистка страниц через флаг --gcthreads=X,1, мы выполняем системные вызовы madvise в фоновом потоке очистки, одновременно с потоками мутаторов. Во время фазы остановки мира сборщика, страницы, выделенные из пула, которые не содержат живых объектов, изначально помещаются в pool_page_lazily_freed. Затем фоновый поток очистки пробуждается и отвечает за удаление страниц из pool_page_lazily_freed, вызов madvise для них и вставку их в pool_page_freed. Как описано выше, pool_page_lazily_freed также разделяется с потоками мутаторов. Это подразумевает, что при многопоточных нагрузках с высокой аллокацией потоки мутаторов часто избегают ошибки страницы при аллокации (возникающей из-за доступа к свежей mmaped странице или доступа к странице, на которую был вызван madvise), напрямую выделяя страницу из pool_page_lazily_freed, в то время как фоновый поток очистки должен вызвать madvise для уменьшенного числа страниц, поскольку некоторые из них уже были заявлены мутаторами.
Heuristics
GC эвристики настраивают сборщик мусора, изменяя размер интервала выделения между сборками мусора.
Генераторы сборки мусора (GC) измеряют, насколько велик размер кучи после сборки, и устанавливают следующую сборку в соответствии с алгоритмом, описанным на https://dl.acm.org/doi/10.1145/3563323. Вкратце, он утверждает, что целевой размер кучи должен иметь квадратное соотношение с живой кучей, и что он также должен масштабироваться в зависимости от того, насколько быстро сборка мусора освобождает объекты и насколько быстро мутаторы выделяют память. Генераторы измеряют размер кучи, подсчитывая количество страниц, которые используются, и объекты, которые используют malloc. Ранее мы измеряли размер кучи, подсчитывая живые объекты, но это не учитывало фрагментацию, что могло привести к плохим решениям, это также означало, что мы использовали информацию, локальную для потока (выделения), чтобы принимать решения о процессе в целом (когда выполнять сборку мусора), измерение страниц означает, что решение является глобальным.
GC будет выполнять полные сборки, когда размер кучи достигнет 80% от максимально допустимого размера.