JIT Design and Implementation
Этот документ объясняет проектирование и реализацию JIT Julia, после того как завершилась генерация кода и был получен не оптимизированный LLVM IR. JIT отвечает за оптимизацию и компиляцию этого IR в машинный код, а также за связывание его с текущим процессом и предоставление кода для выполнения.
Introduction
JIT отвечает за управление ресурсами компиляции, поиск ранее скомпилированного кода и компиляцию нового кода. Он в основном построен на технологии LLVM On-Request-Compilation (ORCv2), которая поддерживает ряд полезных функций, таких как параллельная компиляция, ленивое компилирование и возможность компилировать код в отдельном процессе. Хотя LLVM предоставляет базовый JIT-компилятор в виде LLJIT, Julia использует многие API ORCv2 напрямую для создания собственного пользовательского JIT-компилятора.
Overview
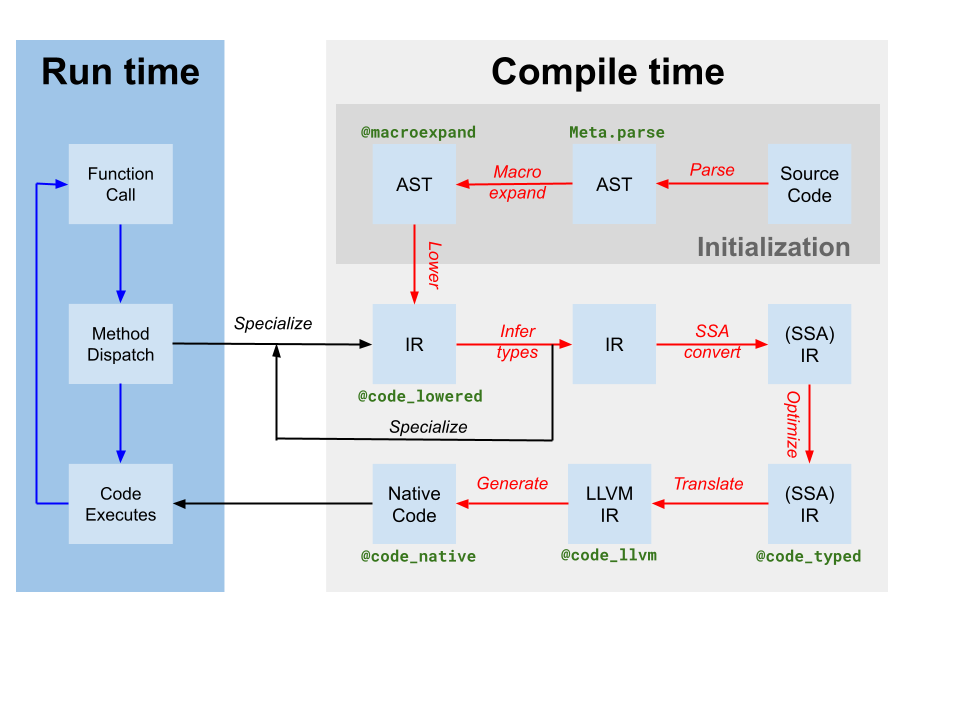
Codegen создает модуль LLVM, содержащий IR для одной или нескольких функций Julia из оригинального SSA IR Julia, полученного в результате вывода типов (обозначенного как translate на диаграмме компилятора выше). Он также создает отображение экземпляра кода на имя функции LLVM. Однако, хотя некоторые оптимизации были применены компилятором на основе Julia к IR Julia, IR LLVM, созданный codegen, все еще содержит множество возможностей для оптимизации. Таким образом, первый шаг, который выполняет JIT, - это запуск независимого от цели конвейера оптимизации[tdp] на модуле LLVM. Затем JIT запускает зависимый от цели конвейер оптимизации, который включает специфические для цели оптимизации и генерацию кода, и выводит объектный файл. Наконец, JIT связывает полученный объектный файл с текущим процессом и делает код доступным для выполнения. Все это контролируется кодом в src/jitlayers.cpp.
В настоящее время только один поток за раз может входить в конвейер оптимизации-компиляции-ссылки из-за ограничений, наложенных одним из наших компоновщиков (RuntimeDyld). Однако JIT разработан для поддержки параллельной оптимизации и компиляции, и ожидается, что ограничение компоновщика будет снято в будущем, когда RuntimeDyld будет полностью заменен на всех платформах.
Optimization Pipeline
Оптимизационный конвейер основан на новом менеджере проходов LLVM, но конвейер настроен под нужды Julia. Конвейер определен в src/pipeline.cpp и в целом проходит через несколько этапов, как подробно описано ниже.
Раннее упрощение
- Эти проходы в основном используются для упрощения IR и канонизации паттернов, чтобы последующие проходы могли легче идентифицировать эти паттерны. Кроме того, различные встроенные вызовы, такие как подсказки по предсказанию ветвлений и аннотации, преобразуются в другие метаданные или другие функции IR.
SimplifyCFG(упрощение графа управления потоком),DCE(устранение мертвого кода) иSROA(скалярная замена агрегатов) являются некоторыми из ключевых игроков здесь.
- Эти проходы в основном используются для упрощения IR и канонизации паттернов, чтобы последующие проходы могли легче идентифицировать эти паттерны. Кроме того, различные встроенные вызовы, такие как подсказки по предсказанию ветвлений и аннотации, преобразуются в другие метаданные или другие функции IR.
Ранняя оптимизация
- Эти проходы, как правило, дешевы и в основном сосредоточены на сокращении количества инструкций в IR и распространении знаний на другие инструкции. Например,
EarlyCSEиспользуется для выполнения устранения общих подвыражений, аInstCombineиInstSimplifyвыполняют ряд небольших оптимизаций в окне, чтобы сделать операции менее затратными.
- Эти проходы, как правило, дешевы и в основном сосредоточены на сокращении количества инструкций в IR и распространении знаний на другие инструкции. Например,
Оптимизация циклов
- Эти проходы канонизируют и упрощают циклы. Циклы часто являются горячим кодом, что делает оптимизацию циклов крайне важной для производительности. Ключевыми игроками здесь являются
LoopRotate,LICM, иLoopFullUnroll. Некоторое устранение проверок границ также происходит здесь, в результате проходаIRCE, который может доказать, что определенные границы никогда не превышаются.
- Эти проходы канонизируют и упрощают циклы. Циклы часто являются горячим кодом, что делает оптимизацию циклов крайне важной для производительности. Ключевыми игроками здесь являются
Скалярная оптимизация
- Пайплайн скалярной оптимизации содержит ряд более дорогих, но более мощных проходов, таких как
GVN(глобальная нумерация значений),SCCP(разреженное условное распространение констант) и еще один раунд устранения проверок границ. Эти проходы дороги, но они часто могут удалить большие объемы кода и сделать векторизацию гораздо более успешной и эффективной. Несколько других проходов упрощения и оптимизации чередуются с более дорогими, чтобы уменьшить объем работы, которую им нужно выполнить.
- Пайплайн скалярной оптимизации содержит ряд более дорогих, но более мощных проходов, таких как
Векторизация
- Automatic vectorization является чрезвычайно мощной трансформацией для кода, требующего интенсивных вычислений на ЦП. Кратко говоря, векторизация позволяет выполнять single instruction on multiple data (SIMD), т.е. выполнять 8 операций сложения одновременно. Однако доказать, что код способен как на векторизацию, так и на получение выгоды от векторизации, сложно, и это сильно зависит от предыдущих этапов оптимизации, чтобы преобразовать IR в состояние, в котором векторизация оправдана.
Внутреннее понижение
- Джулия вставляет ряд пользовательских встроенных функций по таким причинам, как выделение объектов, сборка мусора и обработка исключений. Эти встроенные функции изначально были размещены для того, чтобы сделать возможности оптимизации более очевидными, но теперь они преобразуются в LLVM IR, чтобы позволить IR быть скомпилированным в машинный код.
Очистка
- Эти проходы являются последними шансами для оптимизации и выполняют небольшие оптимизации, такие как распространение слияния умножения и сложения и упрощение деления-остатка. Кроме того, цели, которые не поддерживают числа с плавающей запятой половинной точности, будут иметь свои инструкции половинной точности преобразованными в инструкции одинарной точности здесь, и добавляются проходы для обеспечения поддержки санитайзеров.
Target-Dependent Optimization and Code Generation
LLVM предоставляет оптимизацию, зависящую от целевой платформы, и генерацию машинного кода в одном конвейере, расположенном в TargetMachine для данной платформы. Эти проходы включают выбор инструкций, планирование инструкций, распределение регистров и эмиссию машинного кода. Документация LLVM предоставляет хорошее общее представление о процессе, а исходный код LLVM является лучшим местом для поиска деталей о конвейере и проходах.
Linking
В настоящее время Julia переходит между двумя компоновщиками: старым компоновщиком RuntimeDyld и новым компоновщиком JITLink. JITLink содержит ряд функций, которых нет у RuntimeDyld, таких как параллельная и реентерабельная компоновка, но в настоящее время не имеет хорошей поддержки интеграций профилирования и еще не поддерживает все платформы, которые поддерживает RuntimeDyld. Со временем ожидается, что JITLink полностью заменит RuntimeDyld. Дополнительные сведения о JITLink можно найти в документации LLVM.
Execution
Как только код был связан с текущим процессом, он становится доступным для выполнения. Этот факт становится известным генерирующему codeinst путем соответствующего обновления полей invoke, specsigflags и specptr. Codeinst поддерживают обновление полей invoke, specsigflags и specptr, при условии, что каждая комбинация этих полей, существующая в любой момент времени, действительна для вызова. Это позволяет JIT обновлять эти поля, не аннулируя существующие codeinst, поддерживая потенциальный будущий параллельный JIT. В частности, следующие состояния могут быть действительными:
invokeравно NULL,specsigflagsравно 0b00,specptrравно NULL- Это начальное состояние codeinst и указывает на то, что codeinst еще не был скомпилирован.
invokeне равен нулю,specsigflagsравен 0b00,specptrравен NULL- Это указывает на то, что кодинст не был скомпилирован с какой-либо специализацией, и что кодинст должен быть вызван напрямую. Обратите внимание, что в этом случае
invokeне читает ни поляspecsigflags, ни полеspecptr, и, следовательно, их можно изменять, не аннулируя указательinvoke.
- Это указывает на то, что кодинст не был скомпилирован с какой-либо специализацией, и что кодинст должен быть вызван напрямую. Обратите внимание, что в этом случае
invokeне равен null,specsigflagsравно 0b10,specptrне равен null- Это указывает на то, что код был скомпилирован, но специализированная сигнатура функции была признана ненужной кодогенерацией.
invokeне равен null,specsigflagsравен 0b11,specptrне равен null- Это указывает на то, что код был скомпилирован, и генерация кода посчитала необходимым специализированную сигнатуру функции. Поле
specptrсодержит указатель на специализированную сигнатуру функции. Указательinvokeможет читать как поляspecsigflags, так иspecptr.
- Это указывает на то, что код был скомпилирован, и генерация кода посчитала необходимым специализированную сигнатуру функции. Поле
Кроме того, существует ряд различных переходных состояний, которые возникают в процессе обновления. Чтобы учесть эти потенциальные ситуации, следует использовать следующие шаблоны записи и чтения при работе с этими полями codeinst.
При написании
invoke,specsigflagsиspecptr:- Выполните атомарную операцию сравнения и обмена для specptr, предполагая, что старое значение было NULL. Эта операция сравнения и обмена должна иметь как минимум порядок acquire-release, чтобы обеспечить гарантии порядка оставшихся операций с памятью в записи.
- Если
specptrне равен нулю, прекратите операцию записи и дождитесь записи бита 0b10 вspecsigflags. - Запишите новый низкий бит
specsigflagsв его окончательное значение. Это может быть ослабленная запись. - Запишите новый указатель
invokeв его окончательное значение. Это должно иметь как минимум порядок памяти release для синхронизации с чтениямиinvoke. - Установите второй бит
specsigflagsв 1. Это должно быть как минимум упорядочивание памяти для синхронизации с чтениямиspecsigflags. Этот шаг завершает операцию записи и сообщает всем другим потокам, что все поля были установлены.
При чтении всех
invoke,specsigflagsиspecptr:- Прочитайте поле
invokeс как минимум порядком памяти acquire. Эта загрузка будет называтьсяinitial_invoke. - Если
initial_invokeравно NULL, код не может быть выполнен.invokeравно NULL,specsigflagsможет рассматриваться как 0b00,specptrможет рассматриваться как NULL. - Прочитайте поле
specptrс как минимум порядком памяти acquire. - Если
specptrравен NULL, то указательinitial_invokeне должен полагаться наspecptrдля гарантии корректного выполнения. Следовательно,invokeне равен NULL,specsigflagsможет рассматриваться как 0b00,specptrможет рассматриваться как NULL. - Если
specptrне равен нулю, тоinitial_invokeможет не быть конечным полемinvoke, которое используетspecptr. Это может произойти, еслиspecptrбыл записан, ноinvokeеще не был записан. Поэтому необходимо ожидать второго битаspecsigflags, пока он не будет установлен в 1 с как минимум порядком памяти acquire. - Перечитайте поле
invokeс как минимум порядком памяти acquire. Эта загрузка будет называтьсяfinal_invoke. - Прочитайте поле
specsigflagsс любым порядком памяти. invokeэтоfinal_invoke,specsigflagsэто значение, считанное на шаге 7,specptrэто значение, считанное на шаге 3.
- Прочитайте поле
При обновлении
specptrна другой, но эквивалентный указатель функции:- Выполните операцию release store нового указателя функции в
specptr. Состояния гонки здесь должны быть безвредными, так как старый указатель функции должен оставаться действительным, и любые новые также должны быть действительными. Как только указатель записан вspecptr, он всегда должен быть вызываемым, независимо от того, будет ли он позже перезаписан.
- Выполните операцию release store нового указателя функции в
Хотя эти шаги записи, чтения и обновления сложны, они обеспечивают возможность JIT обновлять codeinsts без аннулирования существующих codeinsts и обновлять codeinsts без аннулирования существующих invoke указателей. Это позволяет JIT потенциально повторно оптимизировать функции на более высоких уровнях оптимизации в будущем, а также позволит JIT поддерживать параллельную компиляцию функций в будущем.
- tdpThis is not a totally-target independent pipeline, as transformations such as vectorization rely upon target information such as vector register width and cost modeling. Additionally, codegen itself makes a few target-dependent assumptions, and the optimization pipeline will take advantage of that knowledge.