Inference
How inference works
В компиляторе Julia "вывод типов" относится к процессу определения типов последующих значений на основе типов входных значений. Подход Julia к выводу типов был описан в блогах ниже:
- Shows a simplified implementation of the data-flow analysis algorithm, that Julia's type inference routine is based on.
- Gives a high level view of inference with a focus on its inter-procedural convergence guarantee.
- Explains a refinement on the algorithm introduced in 2.
Debugging compiler.jl
Вы можете начать сессию Julia, отредактировать compiler/*.jl (например, чтобы вставить операторы print), а затем заменить Core.Compiler в вашей текущей сессии, перейдя в base и выполнив include("compiler/compiler.jl"). Этот трюк обычно приводит к гораздо более быстрой разработке, чем если бы вы пересобирали Julia для каждого изменения.
В качестве альтернативы вы можете использовать пакет Revise.jl для отслеживания изменений компилятора, используя команду Revise.track(Core.Compiler) в начале вашей сессии Julia. Как объясняется в Revise documentation, изменения в компиляторе будут отражены, когда измененные файлы будут сохранены.
Удобной точкой входа в вывод является typeinf_code. Вот демонстрация выполнения вывода на convert(Int, UInt(1)):
# Get the method
atypes = Tuple{Type{Int}, UInt} # argument types
mths = methods(convert, atypes) # worth checking that there is only one
m = first(mths)
# Create variables needed to call `typeinf_code`
interp = Core.Compiler.NativeInterpreter()
sparams = Core.svec() # this particular method doesn't have type-parameters
run_optimizer = true # run all inference optimizations
types = Tuple{typeof(convert), atypes.parameters...} # Tuple{typeof(convert), Type{Int}, UInt}
Core.Compiler.typeinf_code(interp, m, types, sparams, run_optimizer)Если ваши приключения отладки требуют MethodInstance, вы можете найти его, вызвав Core.Compiler.specialize_method, используя многие из вышеупомянутых переменных. Объект CodeInfo можно получить с помощью
# Returns the CodeInfo object for `convert(Int, ::UInt)`:
ci = (@code_typed convert(Int, UInt(1)))[1]The inlining algorithm (inline_worthy)
Большая часть самой сложной работы по инлайнингу выполняется в ssa_inlining_pass!. Однако, если ваш вопрос заключается в том, "почему моя функция не была инлайнена?", то вам, скорее всего, будет интересно inline_worthy, которое принимает решение о том, инлайнить вызов функции или нет.
inline_worthy реализует модель затрат, где "дешевые" функции встраиваются; более конкретно, мы встраиваем функции, если их предполагаемое время выполнения не велико по сравнению с временем, которое потребовалось бы для issue a call, если бы они не были встроены. Модель затрат чрезвычайно проста и игнорирует многие важные детали: например, все циклы for анализируются так, как будто они будут выполнены один раз, а стоимость if...else...end включает суммарную стоимость всех ветвей. Также стоит отметить, что в настоящее время у нас нет набора функций, подходящих для тестирования того, насколько хорошо модель затрат предсказывает фактическую стоимость времени выполнения, хотя BaseBenchmarks предоставляет множество косвенной информации о успехах и неудачах любых модификаций алгоритма встраивания.
Основой модели затрат является таблица поиска, реализованная в add_tfunc и его вызовах, которая назначает оценочную стоимость (измеряемую в циклах ЦП) каждой из встроенных функций Julia. Эти затраты основаны на standard ranges for common architectures (см. Agner Fog's analysis для получения дополнительной информации).
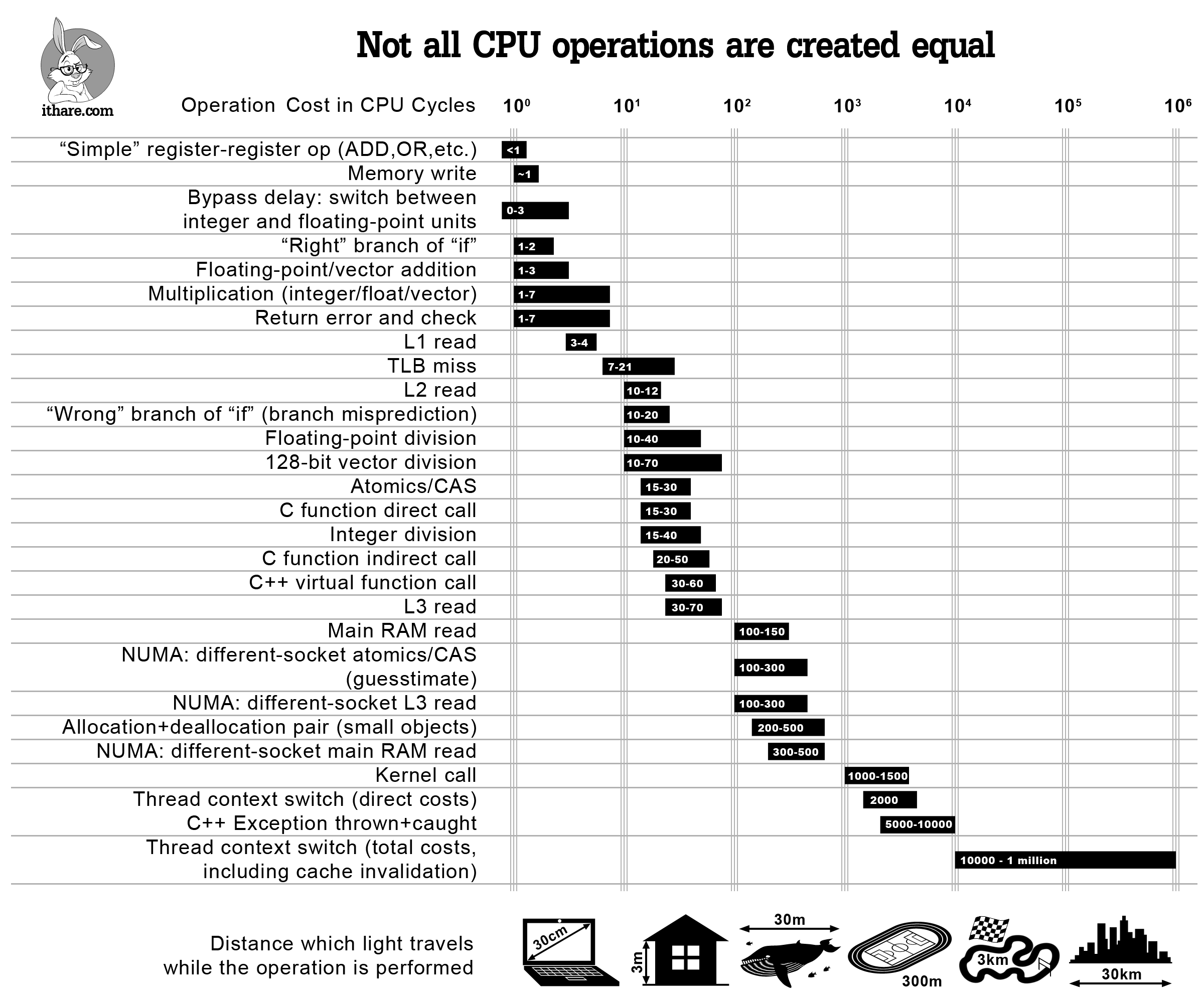{kind=link}
Мы дополняем эту таблицу низкоуровневых запросов рядом специальных случаев. Например, выражение :invoke (вызов, для которого все входные и выходные типы были выведены заранее) имеет фиксированную стоимость (в настоящее время 20 циклов). В отличие от этого, выражение :call, для функций, отличных от встроенных/базовых, указывает на то, что вызов потребует динамической диспетчеризации, в этом случае мы устанавливаем стоимость, заданную Params.inline_nonleaf_penalty (в настоящее время установлена на 1000). Обратите внимание, что это не "оценка по первым принципам" сырой стоимости динамической диспетчеризации, а всего лишь эвристика, указывающая на то, что динамическая диспетчеризация чрезвычайно дорога.
Каждое утверждение анализируется на общую стоимость в функции, называемой statement_cost. Вы можете отобразить стоимость, связанную с каждым утверждением, следующим образом:
julia> Base.print_statement_costs(stdout, map, (typeof(sqrt), Tuple{Int},)) # map(sqrt, (2,))
map(f, t::Tuple{Any}) @ Base tuple.jl:281
0 1 ─ %1 = $(Expr(:boundscheck, true))::Bool
0 │ %2 = Base.getfield(_3, 1, %1)::Int64
1 │ %3 = Base.sitofp(Float64, %2)::Float64
0 │ %4 = Base.lt_float(%3, 0.0)::Bool
0 └── goto #3 if not %4
0 2 ─ invoke Base.Math.throw_complex_domainerror(:sqrt::Symbol, %3::Float64)::Union{}
0 └── unreachable
20 3 ─ %8 = Base.Math.sqrt_llvm(%3)::Float64
0 └── goto #4
0 4 ─ goto #5
0 5 ─ %11 = Core.tuple(%8)::Tuple{Float64}
0 └── return %11
Стоимость линий указана в левом столбце. Это включает последствия инлайнинга и другие формы оптимизации.