Garbage Collection in Julia
Introduction
Julia hat einen nicht bewegenden, teilweise konkurrierenden, parallelen, generationalen und größtenteils präzisen Mark-and-Sweep-Sammler (eine Schnittstelle für konservatives Stapelscannen wird als Option für Benutzer bereitgestellt, die Julia aus C aufrufen möchten).
Allocation
Julia verwendet zwei Arten von Allokatoren, wobei die Größe der Allokierungsanfrage bestimmt, welcher verwendet wird. Objekte bis zu 2k Bytes werden in einem pro-Thread-Freilisten-Pool-Allokator zugewiesen, während Objekte, die größer als 2k Bytes sind, über libc malloc zugewiesen werden.
Julias Pool-Allocator partitioniert Objekte in verschiedene Größenklassen, sodass eine von dem Pool-Allocator verwaltete Speicherseite (die 4 Betriebssystemseiten auf 64-Bit-Plattformen umfasst) nur Objekte derselben Größenklasse enthält. Jede Speicherseite des Pool-Allocators ist mit einigen Seitenmetadaten gekoppelt, die in thread-sicheren, lockfreien Listen gespeichert sind. Die Seitenmetadaten enthalten Informationen wie beispielsweise, ob die Seite überhaupt lebende Objekte hat, die Anzahl der freien Slots und die Offsets zu den ersten und letzten Objekten in der Freiliste, die sich auf dieser Seite befindet. Diese Metadaten werden verwendet, um die Sammlung zu optimieren: Eine Seite, die überhaupt keine lebenden Objekte hat, kann beispielsweise ohne Scannen an das Betriebssystem zurückgegeben werden.
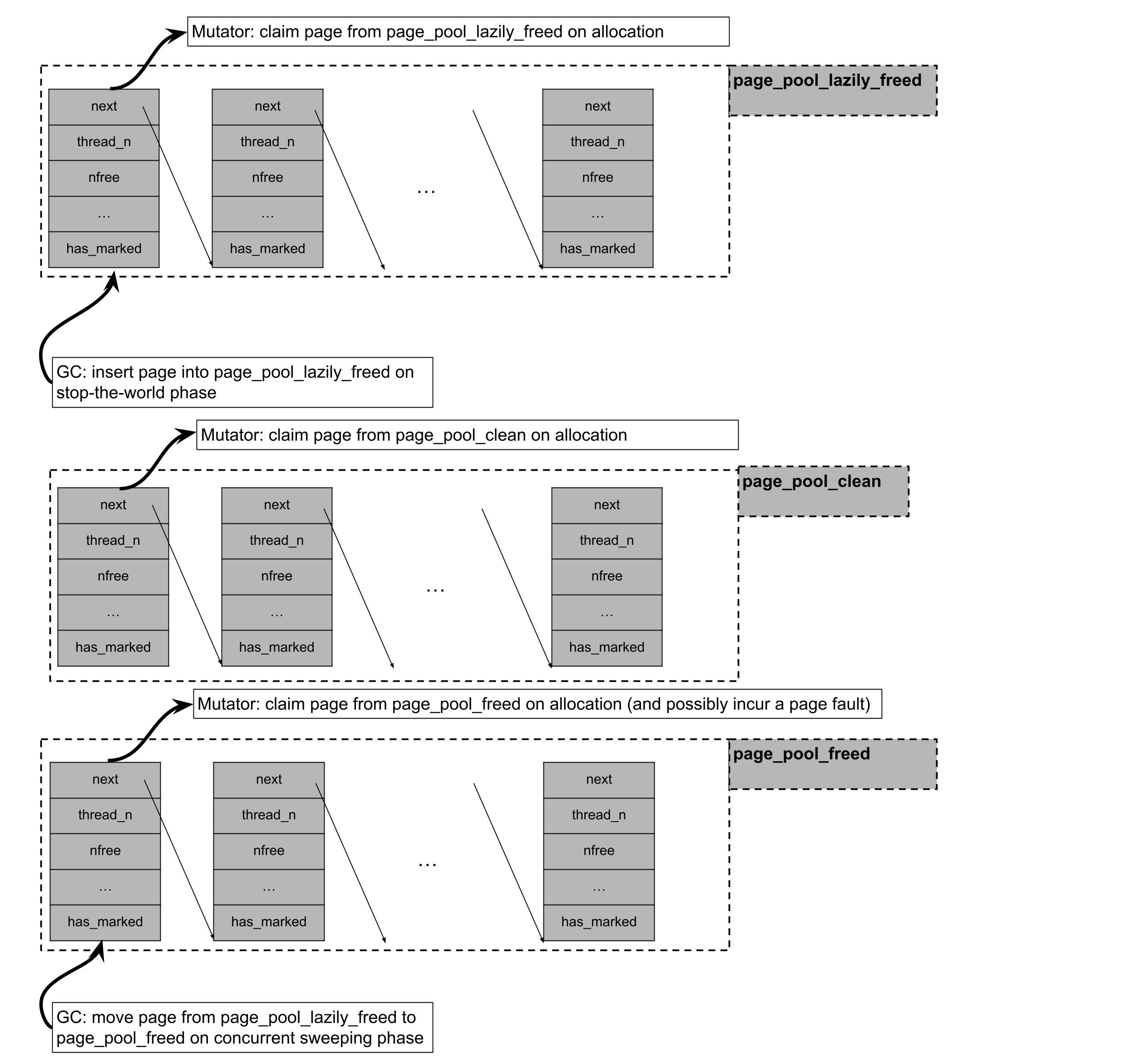
Während eine Seite, die keine Objekte hat, an das Betriebssystem zurückgegeben werden kann, ist ihre zugehörige Metadaten dauerhaft zugewiesen und kann länger leben als die gegebene Seite. Wie oben erwähnt, werden die Metadaten für zugewiesene Seiten in thread-sicheren, lockfreien Listen gespeichert. Die Metadaten für freie Seiten können jedoch in drei separate lockfreie Listen gespeichert werden, abhängig davon, ob die Seite zugeordnet, aber nie zugegriffen wurde (page_pool_clean), oder ob die Seite faul gereinigt wurde und darauf wartet, von einem Hintergrund-GC-Thread beraten zu werden (page_pool_lazily_freed), oder ob die Seite beraten wurde (page_pool_freed).
Julias Pool-Allocator folgt einer "gestuften" Zuteilungsdisziplin. Bei der Anforderung einer Speicherseite für den Pool-Allocator wird Julia:
Versuchen Sie, eine Seite aus
page_pool_lazily_freedzu beanspruchen, die Seiten enthält, die in der letzten Stop-the-World-Phase leer waren, aber noch nicht von einem konkurrierenden Sweeper-GC-Thread bearbeitet wurden.Wenn es fehlschlägt, eine Seite aus
page_pool_lazily_freedzu beanspruchen, wird es versuchen, eine Seite austhe page_pool_cleanzu beanspruchen, die Seiten enthält, die bei einer vorherigen Seitenzuweisungsanforderung mmaped wurden, aber nie zugegriffen wurden.Wenn es fehlschlägt, eine Seite aus
pool_page_cleanund auspage_pool_lazily_freedzu beanspruchen, wird es versuchen, eine Seite auspage_pool_freedzu beanspruchen, die Seiten enthält, die bereits von einem konkurrierenden Sweeper-GC-Thread madvised wurden und deren zugrunde liegende virtuelle Adresse recycelt werden kann.Wenn es in allen oben genannten Versuchen fehlgeschlagen ist, wird es einen Batch von Seiten mmapen, eine Seite für sich beanspruchen und die verbleibenden Seiten in
page_pool_cleaneinfügen.
Marking and Generational Collection
Julias Mark-Phase wird durch eine parallele iterative Tiefensuche über den Objektgraphen implementiert. Julias Sammler ist nicht beweglich, daher kann das Alter eines Objekts nicht allein durch den Speicherbereich, in dem sich das Objekt befindet, bestimmt werden, sondern muss irgendwie im Objektkopf oder in einer Nebentabelle kodiert werden. Die niedrigsten zwei Bits des Objektkopfs werden verwendet, um jeweils ein Markierungsbit zu speichern, das gesetzt wird, wenn ein Objekt während der Markierungsphase gescannt wird, und ein Altersbit für die generative Sammlung.
Die generationalen Sammlungen werden durch Sticky Bits implementiert: Objekte werden nur in den Mark-Stack geschoben und somit nachverfolgt, wenn ihre Mark-Bits nicht gesetzt sind. Wenn Objekte die älteste Generation erreichen, werden ihre Mark-Bits während des sogenannten "Quick-Sweep" nicht zurückgesetzt, was dazu führt, dass diese Objekte in einer nachfolgenden Markierungsphase nicht nachverfolgt werden. Ein "Full-Sweep" hingegen führt dazu, dass die Mark-Bits aller Objekte zurückgesetzt werden, was dazu führt, dass alle Objekte in einer nachfolgenden Markierungsphase nachverfolgt werden. Objekte werden während jeder Sweep-Phase, die sie überstehen, in die nächste Generation befördert. Auf der Mutator-Seite werden Feldschreibvorgänge durch eine Schreibbarriere abgefangen, die die Adresse eines Objekts in ein pro-Thread-Erinnerungsset schiebt, wenn das Objekt in der letzten Generation ist und wenn das Objekt im zu schreibenden Feld es nicht ist. Objekte in diesem Erinnerungsset werden dann während der Markierungsphase nachverfolgt.
Sweeping
Die Bereinigung von Objektpools für Julia kann in zwei Kategorien unterteilt werden: Wenn eine bestimmte Seite, die vom Pool-Allocator verwaltet wird, mindestens ein lebendes Objekt enthält, muss eine Freiliste durch ihre toten Objekte geführt werden; wenn eine bestimmte Seite überhaupt keine lebenden Objekte enthält, kann ihr zugrunde liegender physischer Speicher durch beispielsweise die Verwendung von madvise-Systemaufrufen unter Linux an das Betriebssystem zurückgegeben werden.
Die erste Kategorie des Sweepings wird durch Work-Stealing parallelisiert. Für die zweite Kategorie des Sweepings, wenn das gleichzeitige Seiten-Sweeping durch das Flag --gcthreads=X,1 aktiviert ist, führen wir die madvise-Systemaufrufe in einem Hintergrund-Sweeper-Thread durch, der gleichzeitig mit den Mutator-Threads arbeitet. Während der Stop-the-World-Phase des Collectors werden Seiten, die im Pool zugewiesen sind und keine lebenden Objekte enthalten, zunächst in pool_page_lazily_freed geschoben. Der Hintergrund-Sweeping-Thread wird dann geweckt und ist dafür verantwortlich, Seiten aus pool_page_lazily_freed zu entfernen, madvise auf ihnen aufzurufen und sie in pool_page_freed einzufügen. Wie oben beschrieben, wird pool_page_lazily_freed auch mit den Mutator-Threads geteilt. Dies impliziert, dass bei allocationsintensiven, mehrthreadigen Workloads die Mutator-Threads oft einen Seitenfehler bei der Zuweisung (der von einem Zugriff auf eine frisch mmaped Seite oder einem Zugriff auf eine madvised Seite stammt) vermeiden würden, indem sie direkt von einer Seite in pool_page_lazily_freed zuweisen, während der Hintergrund-Sweeper-Thread eine reduzierte Anzahl von Seiten madvise muss, da einige von ihnen bereits von den Mutatoren beansprucht wurden.
Heuristics
GC-Heuristiken stimmen die GC ab, indem sie die Größe des Zuweisungsintervalls zwischen den Garbage Collections ändern.
Die GC-Heuristiken messen, wie groß die Heap-Größe nach einer Sammlung ist, und setzen die nächste Sammlung gemäß dem Algorithmus, der unter https://dl.acm.org/doi/10.1145/3563323 beschrieben ist. Zusammenfassend argumentiert er, dass das Ziel des Heaps eine Quadratwurzelbeziehung mit dem lebenden Heap haben sollte und dass es auch entsprechend der Geschwindigkeit, mit der der GC Objekte freigibt, und der Geschwindigkeit, mit der die Mutatoren Allokationen vornehmen, skaliert werden sollte. Die Heuristiken messen die Heap-Größe, indem sie die Anzahl der verwendeten Seiten und die Objekte zählen, die malloc verwenden. Zuvor haben wir die Heap-Größe gemessen, indem wir die lebenden Objekte gezählt haben, aber das berücksichtigt nicht die Fragmentierung, die zu schlechten Entscheidungen führen könnte. Das bedeutete auch, dass wir threadlokale Informationen (Allokationen) verwendeten, um Entscheidungen über einen prozessweiten Kontext (wann GC durchgeführt werden soll) zu treffen. Die Messung von Seiten bedeutet, dass die Entscheidung global ist.
Die GC führt vollständige Sammlungen durch, wenn die Heap-Größe 80 % der maximal erlaubten Größe erreicht.