Inference
How inference works
In Julia-Compiler bezieht sich "Typinferenz" auf den Prozess, die Typen späterer Werte aus den Typen der Eingabewerte abzuleiten. Julias Ansatz zur Inferenz wurde in den folgenden Blogbeiträgen beschrieben:
- Shows a simplified implementation of the data-flow analysis algorithm, that Julia's type inference routine is based on.
- Gives a high level view of inference with a focus on its inter-procedural convergence guarantee.
- Explains a refinement on the algorithm introduced in 2.
Debugging compiler.jl
Sie können eine Julia-Sitzung starten, compiler/*.jl bearbeiten (zum Beispiel um print-Anweisungen einzufügen) und dann Core.Compiler in Ihrer laufenden Sitzung ersetzen, indem Sie zu base navigieren und include("compiler/compiler.jl") ausführen. Dieser Trick führt typischerweise zu einer viel schnelleren Entwicklung, als wenn Sie Julia für jede Änderung neu erstellen.
Alternativ können Sie das Revise.jl-Paket verwenden, um die Änderungen am Compiler zu verfolgen, indem Sie den Befehl Revise.track(Core.Compiler) zu Beginn Ihrer Julia-Sitzung verwenden. Wie im Revise documentation erklärt, werden die Änderungen am Compiler reflektiert, wenn die modifizierten Dateien gespeichert werden.
Ein praktischer Einstiegspunkt in die Inferenz ist typeinf_code. Hier ist eine Demo, die die Inferenz für convert(Int, UInt(1)) ausführt:
# Get the method
atypes = Tuple{Type{Int}, UInt} # argument types
mths = methods(convert, atypes) # worth checking that there is only one
m = first(mths)
# Create variables needed to call `typeinf_code`
interp = Core.Compiler.NativeInterpreter()
sparams = Core.svec() # this particular method doesn't have type-parameters
run_optimizer = true # run all inference optimizations
types = Tuple{typeof(convert), atypes.parameters...} # Tuple{typeof(convert), Type{Int}, UInt}
Core.Compiler.typeinf_code(interp, m, types, sparams, run_optimizer)Wenn Ihre Debugging-Abenteuer ein MethodInstance erfordern, können Sie es abrufen, indem Sie Core.Compiler.specialize_method mit vielen der oben genannten Variablen aufrufen. Ein CodeInfo-Objekt kann mit
# Returns the CodeInfo object for `convert(Int, ::UInt)`:
ci = (@code_typed convert(Int, UInt(1)))[1]The inlining algorithm (inline_worthy)
Ein Großteil der härtesten Arbeit für das Inlining erfolgt in ssa_inlining_pass!. Wenn Ihre Frage jedoch lautet: "Warum wurde meine Funktion nicht inline gesetzt?", dann werden Sie höchstwahrscheinlich an inline_worthy interessiert sein, das die Entscheidung trifft, ob der Funktionsaufruf inline gesetzt wird oder nicht.
inline_worthy implementiert ein Kostenmodell, bei dem "günstige" Funktionen inline gesetzt werden; genauer gesagt, wir setzen Funktionen inline, wenn ihre erwartete Laufzeit im Vergleich zu der Zeit, die es dauern würde, issue a call zu ihnen, wenn sie nicht inline gesetzt würden, nicht groß ist. Das Kostenmodell ist extrem einfach und ignoriert viele wichtige Details: Zum Beispiel werden alle for-Schleifen so analysiert, als ob sie einmal ausgeführt werden, und die Kosten eines if...else...end umfassen die summierten Kosten aller Zweige. Es ist auch erwähnenswert, dass wir derzeit über eine Suite von Funktionen verfügen, die geeignet sind, zu testen, wie gut das Kostenmodell die tatsächlichen Laufzeitkosten vorhersagt, obwohl BaseBenchmarks eine große Menge an indirekten Informationen über die Erfolge und Misserfolge von Änderungen am Inlining-Algorithmus bietet.
Die Grundlage des Kostenmodells ist eine Nachschlagetabelle, die in add_tfunc und seinen Aufrufern implementiert ist und jedem von Julias intrinsischen Funktionen eine geschätzte Kosten (gemessen in CPU-Zyklen) zuweist. Diese Kosten basieren auf standard ranges for common architectures (siehe Agner Fog's analysis für weitere Details).
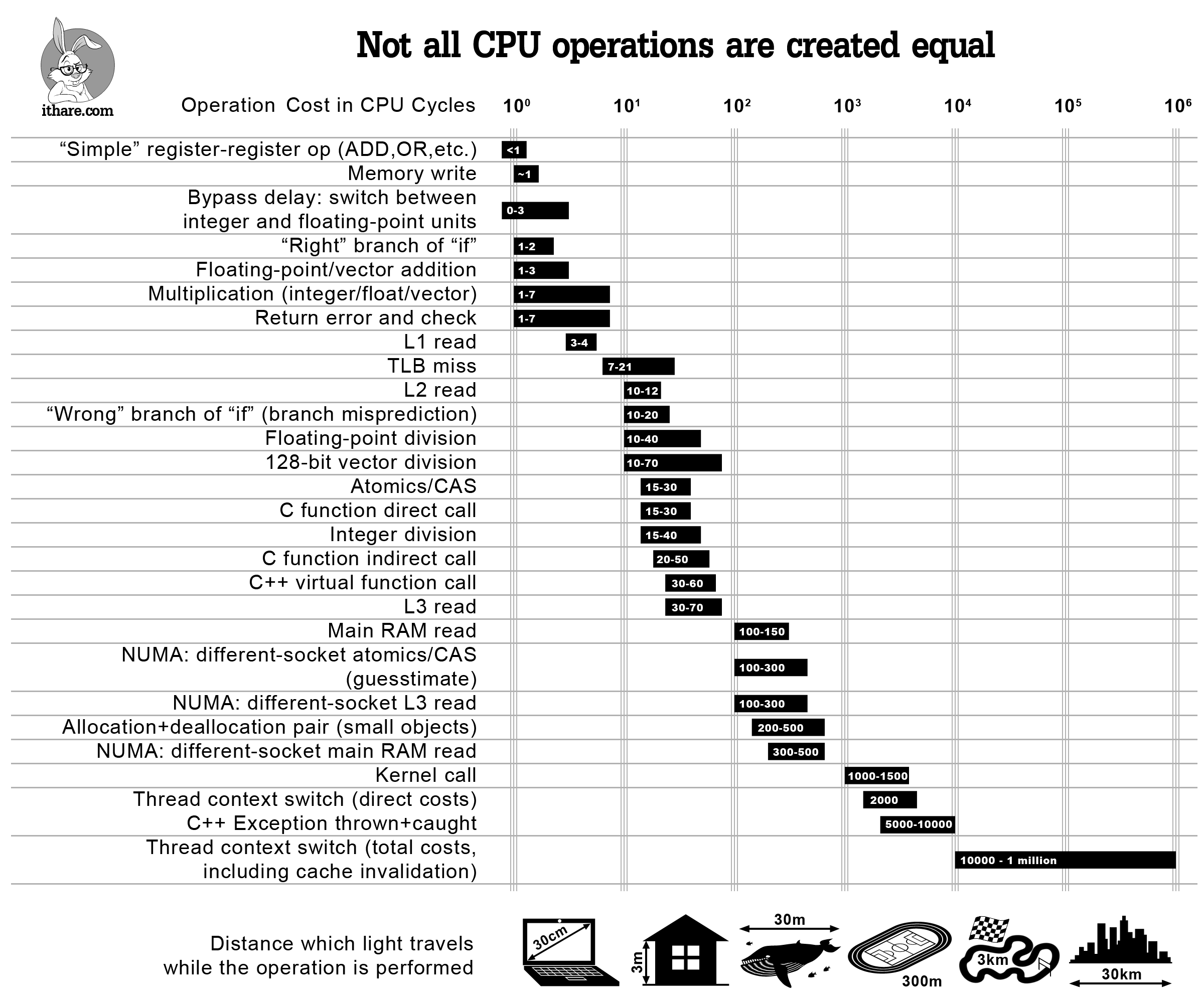{kind=link}
Wir ergänzen diese Low-Level-Lookup-Tabelle mit einer Reihe von Sonderfällen. Zum Beispiel wird ein :invoke-Ausdruck (ein Aufruf, für den alle Eingabe- und Ausgabetypen im Voraus abgeleitet wurden) mit einem festen Kostenpunkt (derzeit 20 Zyklen) belegt. Im Gegensatz dazu zeigt ein :call-Ausdruck für Funktionen, die keine Intrinsics/Builtins sind, an, dass der Aufruf eine dynamische Dispatch erfordert, in diesem Fall setzen wir die Kosten auf den von Params.inline_nonleaf_penalty festgelegten Wert (derzeit auf 1000 gesetzt). Beachten Sie, dass dies keine "Erstprinzipien"-Schätzung der Rohkosten des dynamischen Dispatch ist, sondern lediglich eine Heuristik, die darauf hinweist, dass dynamischer Dispatch extrem teuer ist.
Jede Aussage wird in einer Funktion namens statement_cost auf ihre Gesamtkosten analysiert. Sie können die mit jeder Aussage verbundenen Kosten wie folgt anzeigen:
julia> Base.print_statement_costs(stdout, map, (typeof(sqrt), Tuple{Int},)) # map(sqrt, (2,))
map(f, t::Tuple{Any}) @ Base tuple.jl:281
0 1 ─ %1 = $(Expr(:boundscheck, true))::Bool
0 │ %2 = Base.getfield(_3, 1, %1)::Int64
1 │ %3 = Base.sitofp(Float64, %2)::Float64
0 │ %4 = Base.lt_float(%3, 0.0)::Bool
0 └── goto #3 if not %4
0 2 ─ invoke Base.Math.throw_complex_domainerror(:sqrt::Symbol, %3::Float64)::Union{}
0 └── unreachable
20 3 ─ %8 = Base.Math.sqrt_llvm(%3)::Float64
0 └── goto #4
0 4 ─ goto #5
0 5 ─ %11 = Core.tuple(%8)::Tuple{Float64}
0 └── return %11
Die Zeilenkosten befinden sich in der linken Spalte. Dies umfasst die Folgen von Inlining und anderen Formen der Optimierung.