JIT Design and Implementation
Dieses Dokument erklärt das Design und die Implementierung von Julias JIT, nachdem die Codegenerierung abgeschlossen ist und unoptimierter LLVM IR produziert wurde. Der JIT ist verantwortlich für die Optimierung und Kompilierung dieses IR in Maschinencode und für das Verlinken in den aktuellen Prozess sowie dafür, den Code für die Ausführung verfügbar zu machen.
Introduction
Der JIT ist verantwortlich für das Management von Kompilierungsressourcen, das Nachschlagen von zuvor kompiliertem Code und das Kompilieren von neuem Code. Er basiert hauptsächlich auf der On-Request-Compilation (ORCv2) Technologie von LLVM, die Unterstützung für eine Reihe nützlicher Funktionen wie parallele Kompilierung, verzögerte Kompilierung und die Möglichkeit bietet, Code in einem separaten Prozess zu kompilieren. Obwohl LLVM einen grundlegenden JIT-Compiler in Form von LLJIT bereitstellt, verwendet Julia viele ORCv2-APIs direkt, um seinen eigenen benutzerdefinierten JIT-Compiler zu erstellen.
Overview
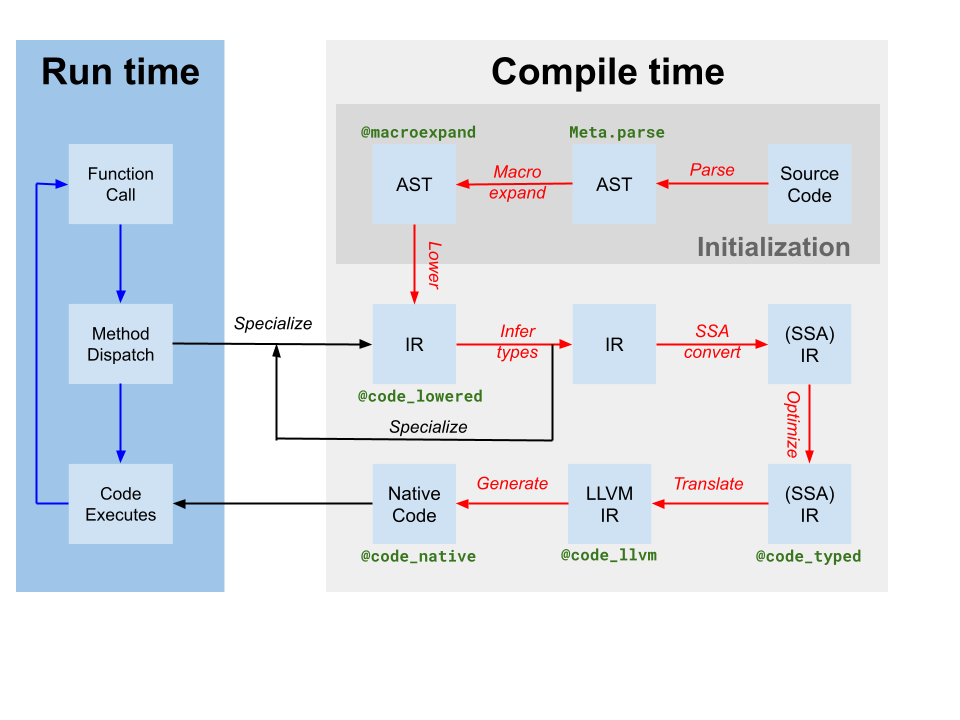
Codegen erzeugt ein LLVM-Modul, das IR für eine oder mehrere Julia-Funktionen aus dem ursprünglichen Julia SSA IR enthält, das durch Typinferenz erzeugt wurde (im Compiler-Diagramm oben als Übersetzung gekennzeichnet). Es produziert auch eine Zuordnung von Code-Instanzen zu LLVM-Funktionsnamen. Obwohl einige Optimierungen vom Julia-basierten Compiler auf Julia IR angewendet wurden, enthält das von Codegen erzeugte LLVM IR immer noch viele Möglichkeiten zur Optimierung. Daher ist der erste Schritt, den der JIT unternimmt, die Ausführung einer zielunabhängigen Optimierungspipeline[tdp] auf dem LLVM-Modul. Anschließend führt der JIT eine zielabhängige Optimierungspipeline aus, die ziel-spezifische Optimierungen und die Codegenerierung umfasst, und gibt eine Objektdatei aus. Schließlich verknüpft der JIT die resultierende Objektdatei mit dem aktuellen Prozess und macht den Code für die Ausführung verfügbar. All dies wird durch Code in src/jitlayers.cpp gesteuert.
Derzeit ist es nur einem Thread gleichzeitig erlaubt, die Optimize-Compile-Link-Pipeline zu betreten, aufgrund von Einschränkungen, die von einem unserer Linker (RuntimeDyld) auferlegt werden. Der JIT ist jedoch so konzipiert, dass er gleichzeitige Optimierung und Kompilierung unterstützt, und die Linker-Einschränkung wird voraussichtlich in Zukunft aufgehoben, wenn RuntimeDyld auf allen Plattformen vollständig ersetzt wurde.
Optimization Pipeline
Die Optimierungspipeline basiert auf dem neuen Pass-Manager von LLVM, ist jedoch an die Bedürfnisse von Julia angepasst. Die Pipeline ist in src/pipeline.cpp definiert und verläuft grob durch eine Reihe von Phasen, die im Folgenden detailliert beschrieben werden.
- Frühe Vereinfachung
- Diese Pässe werden hauptsächlich verwendet, um die IR zu vereinfachen und Muster zu kanonisieren, damit spätere Pässe diese Muster leichter identifizieren können. Darüber hinaus werden verschiedene intrinsische Aufrufe wie Branch-Prediction-Hinweise und Anmerkungen in andere Metadaten oder andere IR-Funktionen umgewandelt.
SimplifyCFG(Kontrollflussgraph vereinfachen),DCE(tote Codeeliminierung) undSROA(skalare Ersetzung von Aggregaten) sind einige der Schlüsselakteure hier.
- Diese Pässe werden hauptsächlich verwendet, um die IR zu vereinfachen und Muster zu kanonisieren, damit spätere Pässe diese Muster leichter identifizieren können. Darüber hinaus werden verschiedene intrinsische Aufrufe wie Branch-Prediction-Hinweise und Anmerkungen in andere Metadaten oder andere IR-Funktionen umgewandelt.
- Frühe Optimierung
- Diese Pässe sind typischerweise günstig und konzentrieren sich hauptsächlich darauf, die Anzahl der Anweisungen im IR zu reduzieren und Wissen auf andere Anweisungen zu propagieren. Zum Beispiel wird
EarlyCSEverwendet, um die Eliminierung gemeinsamer Teilausdrücke durchzuführen, undInstCombinesowieInstSimplifyführen eine Reihe von kleinen Peephole-Optimierungen durch, um Operationen weniger kostspielig zu machen.
- Diese Pässe sind typischerweise günstig und konzentrieren sich hauptsächlich darauf, die Anzahl der Anweisungen im IR zu reduzieren und Wissen auf andere Anweisungen zu propagieren. Zum Beispiel wird
- Schleifenoptimierung
- Diese Pässe kanonisieren und vereinfachen Schleifen. Schleifen sind oft heißer Code, was die Schleifenoptimierung für die Leistung äußerst wichtig macht. Wichtige Akteure hierbei sind
LoopRotate,LICMundLoopFullUnroll. Einige Eliminierungen von Bereichsprüfungen finden hier ebenfalls statt, als Ergebnis desIRCEPasses, der beweisen kann, dass bestimmte Grenzen niemals überschritten werden.
- Diese Pässe kanonisieren und vereinfachen Schleifen. Schleifen sind oft heißer Code, was die Schleifenoptimierung für die Leistung äußerst wichtig macht. Wichtige Akteure hierbei sind
- Skalaroptimierung
- Die skalare Optimierungspipeline enthält eine Reihe von teureren, aber leistungsstärkeren Durchläufen wie
GVN(globale Wertnummerierung),SCCP(sparse bedingte konstante Propagation) und eine weitere Runde der Eliminierung von Bereichsprüfungen. Diese Durchläufe sind teuer, können jedoch oft große Mengen an Code entfernen und die Vektorisierung viel erfolgreicher und effektiver machen. Mehrere andere Vereinfachungs- und Optimierungsdurchläufe durchziehen die teureren, um die Menge an Arbeit, die sie leisten müssen, zu reduzieren.
- Die skalare Optimierungspipeline enthält eine Reihe von teureren, aber leistungsstärkeren Durchläufen wie
- Vektorisierung
- Automatic vectorization ist eine äußerst leistungsstarke Transformation für CPU-intensive Code. Kurz gesagt, ermöglicht die Vektorisierung die Ausführung einer single instruction on multiple data (SIMD), z.B. das gleichzeitige Durchführen von 8 Additionsoperationen. Es ist jedoch schwierig, den Code sowohl als vektorisierbar als auch als profitabel für die Vektorisierung nachzuweisen, und dies hängt stark von den vorherigen Optimierungspässen ab, um die IR in einen Zustand zu bringen, in dem sich die Vektorisierung lohnt.
- Intrinsische Senkung
- Julia fügt eine Reihe von benutzerdefinierten Intrinsics ein, aus Gründen wie Objektzuweisung, Garbage Collection und Ausnahmebehandlung. Diese Intrinsics wurden ursprünglich platziert, um Optimierungsmöglichkeiten offensichtlicher zu machen, werden jetzt jedoch in LLVM IR umgewandelt, um zu ermöglichen, dass der IR als Maschinencode ausgegeben wird.
- Aufräumen
- Diese Pässe sind letzte Optimierungen und führen kleine Optimierungen wie die Zusammenführung von Multiplikation und Addition sowie die Vereinfachung von Division und Rest durch. Darüber hinaus werden Zielarchitekturen, die keine Gleitkommazahlen mit halber Genauigkeit unterstützen, ihre Anweisungen mit halber Genauigkeit hier in Anweisungen mit einfacher Genauigkeit umwandeln, und es werden Pässe hinzugefügt, um die Unterstützung von Sanitizern bereitzustellen.
Target-Dependent Optimization and Code Generation
LLVM bietet zielabhängige Optimierung und Maschinen-Code-Generierung im selben Pipeline, die im TargetMachine für eine bestimmte Plattform angesiedelt ist. Diese Pässe umfassen die Auswahl von Anweisungen, die Planung von Anweisungen, die Registerallokation und die Ausgabe von Maschinen-Code. Die LLVM-Dokumentation bietet einen guten Überblick über den Prozess, und der LLVM-Quellcode ist der beste Ort, um Details zur Pipeline und zu den Pässen zu finden.
Linking
Derzeit befindet sich Julia im Übergang zwischen zwei Linkern: dem älteren RuntimeDyld-Linker und dem neueren JITLink-Linker. JITLink enthält eine Reihe von Funktionen, die RuntimeDyld nicht hat, wie z. B. gleichzeitiges und reentrantes Verlinken, bietet jedoch derzeit keine gute Unterstützung für Profilierungsintegrationen und unterstützt noch nicht alle Plattformen, die RuntimeDyld unterstützt. Im Laufe der Zeit wird erwartet, dass JITLink RuntimeDyld vollständig ersetzt. Weitere Details zu JITLink finden Sie in der LLVM-Dokumentation.
Execution
Sobald der Code in den aktuellen Prozess eingebunden ist, steht er zur Ausführung zur Verfügung. Diese Tatsache wird dem generierenden Codeinst bekannt gemacht, indem die Felder invoke, specsigflags und specptr entsprechend aktualisiert werden. Codeinsts unterstützen das Upgrade der Felder invoke, specsigflags und specptr, solange jede Kombination dieser Felder, die zu einem bestimmten Zeitpunkt existiert, gültig aufgerufen werden kann. Dies ermöglicht es dem JIT, diese Felder zu aktualisieren, ohne bestehende Codeinsts ungültig zu machen, und unterstützt einen potenziellen zukünftigen parallelen JIT. Insbesondere können die folgenden Zustände gültig sein:
invokeist NULL,specsigflagsist 0b00,specptrist NULL- Dies ist der ursprüngliche Zustand eines Codeinst, und zeigt an, dass der Codeinst noch nicht kompiliert wurde.
invokeist nicht null,specsigflagsist 0b00,specptrist NULL- Dies weist darauf hin, dass der Codeinst nicht mit einer Spezialisierung kompiliert wurde und dass der Codeinst direkt aufgerufen werden sollte. Beachten Sie, dass in diesem Fall
invokeweder die Felderspecsigflagsnochspecptrliest, und daher können diese geändert werden, ohne deninvoke-Zeiger ungültig zu machen.
- Dies weist darauf hin, dass der Codeinst nicht mit einer Spezialisierung kompiliert wurde und dass der Codeinst direkt aufgerufen werden sollte. Beachten Sie, dass in diesem Fall
invokeist nicht null,specsigflagsist 0b10,specptrist nicht null- Dies deutet darauf hin, dass der Codeinst kompiliert wurde, aber eine spezialisierte Funktionssignatur von der Codegenerierung als unnötig erachtet wurde.
invokeist nicht null,specsigflagsist 0b11,specptrist nicht null- Dies deutet darauf hin, dass der Codeinst kompiliert wurde und eine spezialisierte Funktionssignatur von codegen als notwendig erachtet wurde. Das
specptr-Feld enthält einen Zeiger auf die spezialisierte Funktionssignatur. Derinvoke-Zeiger darf sowohl die Felderspecsigflagsals auchspecptrlesen.
- Dies deutet darauf hin, dass der Codeinst kompiliert wurde und eine spezialisierte Funktionssignatur von codegen als notwendig erachtet wurde. Das
Darüber hinaus gibt es eine Reihe von verschiedenen Übergangszuständen, die während des Aktualisierungsprozesses auftreten. Um diese potenziellen Situationen zu berücksichtigen, sollten die folgenden Schreib- und Lese-Muster verwendet werden, wenn es um diese Codeinst-Felder geht.
- Beim Schreiben von
invoke,specsigflagsundspecptr:- Führen Sie eine atomare Vergleichs- und Austauschoperation von specptr durch, wobei der alte Wert NULL war. Diese Vergleichs- und Austauschoperation sollte mindestens eine Acquire-Release-Reihenfolge haben, um Reihenfolgegarantien für die verbleibenden Speicheroperationen im Schreibvorgang bereitzustellen.
- Wenn
specptrnicht null war, beenden Sie den Schreibvorgang und warten Sie darauf, dass Bit 0b10 vonspecsigflagsgeschrieben wird. - Schreiben Sie das neue niedrigste Bit von
specsigflagsauf seinen endgültigen Wert. Dies kann ein entspannter Schreibvorgang sein. - Schreiben Sie den neuen
invoke-Zeiger auf seinen endgültigen Wert. Dies muss mindestens eine Release-Speicherreihenfolge haben, um mit den Lesevorgängen voninvokezu synchronisieren. - Setzen Sie das zweite Bit von
specsigflagsauf 1. Dies muss mindestens eine Freigabe-Speicherreihenfolge haben, um mit den Lesevorgängen vonspecsigflagszu synchronisieren. Dieser Schritt schließt die Schreiboperation ab und kündigt allen anderen Threads an, dass alle Felder gesetzt wurden.
- Beim Lesen von
invoke,specsigflagsundspecptr:- Lese das
invoke-Feld mit mindestens einer Acquire-Speicherordnung. Dieser Ladevorgang wird alsinitial_invokebezeichnet. - Wenn
initial_invokeNULL ist, ist der codeinst noch nicht ausführbar.invokeist NULL,specsigflagskann als 0b00 behandelt werden,specptrkann als NULL behandelt werden. - Lese das
specptr-Feld mit mindestens einer Acquire-Speicherreihenfolge. - Wenn
specptrNULL ist, darf derinitial_invokeZeiger nicht aufspecptrangewiesen sein, um eine korrekte Ausführung zu gewährleisten. Daher istinvokenicht null,specsigflagskann als 0b00 behandelt werden,specptrkann als NULL behandelt werden. - Wenn
specptrnicht null ist, könnteinitial_invokemöglicherweise nicht das endgültigeinvoke-Feld sein, dasspecptrverwendet. Dies kann auftreten, wennspecptrgeschrieben wurde, aberinvokenoch nicht geschrieben wurde. Daher sollte auf dem zweiten Bit vonspecsigflagsgewartet werden, bis es mit mindestens Acquire-Speicherordnung auf 1 gesetzt ist. - Lese das
invoke-Feld erneut mit mindestens einer Acquire-Speicherordnung. Dieser Ladevorgang wird alsfinal_invokebezeichnet. - Lese das Feld
specsigflagsmit beliebiger Speicheranordnung. invokeistfinal_invoke,specsigflagsist der Wert, der in Schritt 7 gelesen wurde,specptrist der Wert, der in Schritt 3 gelesen wurde.
- Lese das
- Beim Aktualisieren eines
specptrauf einen anderen, aber äquivalenten Funktionszeiger:- Führen Sie einen Release-Store des neuen Funktionszeigers an
specptrdurch. Die Rennen hier müssen harmlos sein, da der alte Funktionszeiger weiterhin gültig sein muss und auch alle neuen gültig sein müssen. Sobald ein Zeiger anspecptrgeschrieben wurde, muss er immer aufrufbar sein, unabhängig davon, ob er später überschrieben wird.
- Führen Sie einen Release-Store des neuen Funktionszeigers an
Obwohl diese Schreib-, Lese- und Aktualisierungsschritte kompliziert sind, stellen sie sicher, dass der JIT Codeinstanzen aktualisieren kann, ohne bestehende Codeinstanzen zu invalidieren, und dass der JIT Codeinstanzen aktualisieren kann, ohne bestehende invoke-Zeiger zu invalidieren. Dies ermöglicht es dem JIT, Funktionen in Zukunft möglicherweise auf höheren Optimierungsstufen erneut zu optimieren, und wird auch dem JIT ermöglichen, in Zukunft die gleichzeitige Kompilierung von Funktionen zu unterstützen.
- tdpThis is not a totally-target independent pipeline, as transformations such as vectorization rely upon target information such as vector register width and cost modeling. Additionally, codegen itself makes a few target-dependent assumptions, and the optimization pipeline will take advantage of that knowledge.