Garbage Collection in Julia
Introduction
Julia 具有一个非移动的、部分并发的、并行的、代际的和大部分精确的标记-清扫收集器(为希望从 C 调用 Julia 的用户提供了保守栈扫描的接口作为选项)。
Allocation
Julia 使用两种类型的分配器,分配请求的大小决定使用哪一种。大小不超过 2k 字节的对象在每个线程的空闲列表池分配器上分配,而大于 2k 字节的对象则通过 libc malloc 分配。
Julia 的池分配器将对象划分为不同的大小类别,因此由池分配器管理的内存页面(在 64 位平台上跨越 4 个操作系统页面)仅包含相同大小类别的对象。池分配器中的每个内存页面都与存储在每个线程无锁列表上的一些页面元数据配对。页面元数据包含的信息包括该页面是否有活动对象、空闲槽的数量,以及该页面中自由列表中第一个和最后一个对象的偏移量。这些元数据用于优化收集阶段:例如,完全没有活动对象的页面可以在不需要扫描的情况下返回给操作系统。
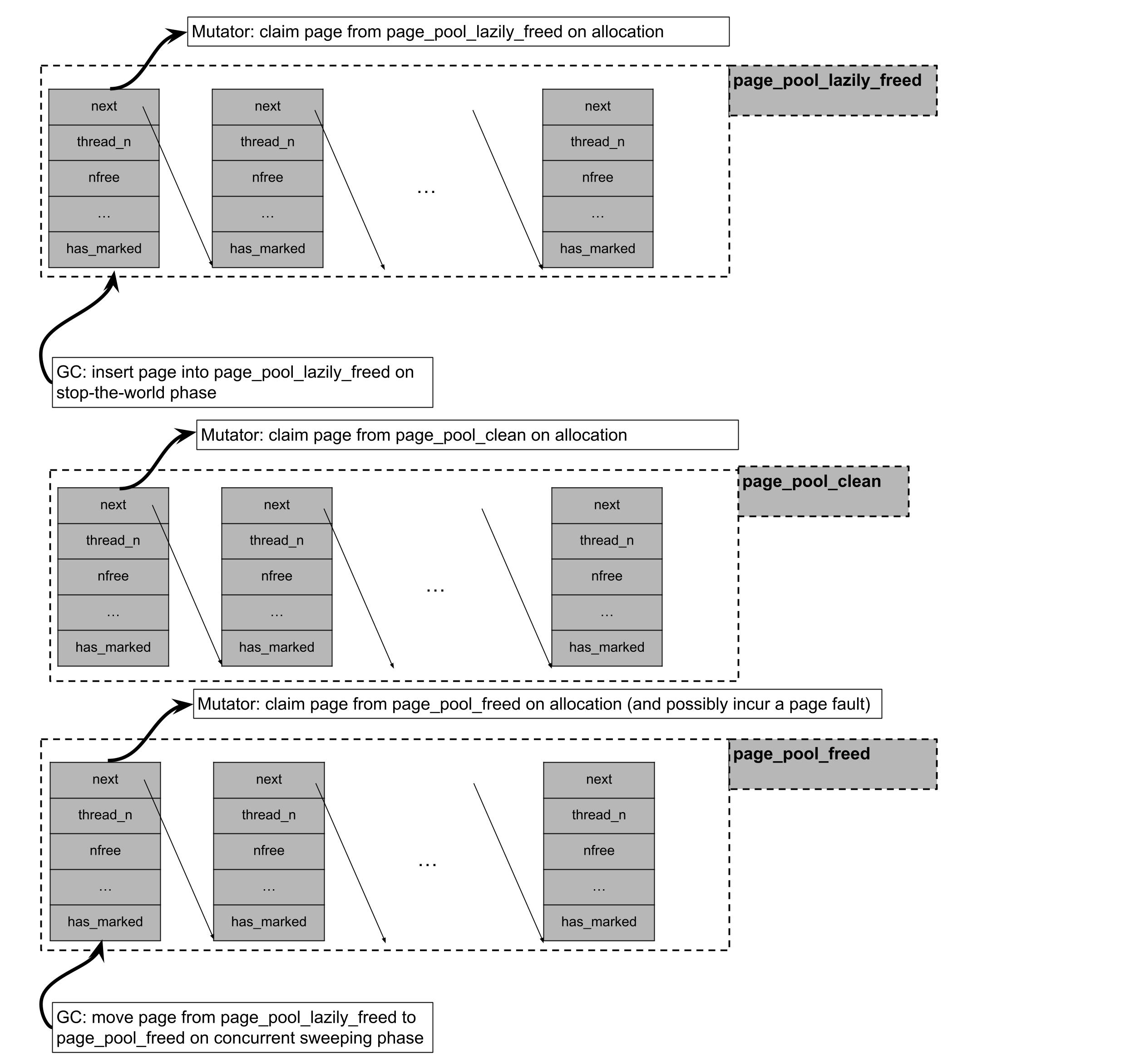
虽然没有对象的页面可以返回给操作系统,但其相关的元数据是永久分配的,可能会比给定页面的生命周期更长。如上所述,已分配页面的元数据存储在每个线程的无锁列表中。然而,空闲页面的元数据可能会根据页面是否已被映射但从未访问过(page_pool_clean),或者页面是否已被懒惰清理并等待后台 GC 线程进行建议(page_pool_lazily_freed),或者页面是否已被建议(page_pool_freed)存储到三个不同的无锁列表中。
Julia的池分配器遵循“分层”分配原则。当请求池分配器的内存页面时,Julia将:
尝试从
page_pool_lazily_freed中申请一个页面,该页面在上一个全停顿阶段为空,但尚未被并发的清扫 GC 线程进行 madvise。如果从
page_pool_lazily_freed声明页面失败,它将尝试从the page_pool_clean声明页面,该池包含在先前的页面分配请求中被 mmap 但从未访问的页面。如果它未能从
pool_page_clean和page_pool_lazily_freed中获取页面,它将尝试从page_pool_freed中获取页面,该页面包含已经被并发清扫 GC 线程建议的页面,并且其底层虚拟地址可以被回收。如果在上述所有尝试中都失败,它将映射一批页面,为自己占用一页,并将剩余的页面插入
page_pool_clean。
Marking and Generational Collection
Julia的标记阶段是通过对对象图进行并行迭代深度优先搜索来实现的。Julia的收集器是非移动的,因此对象的年龄信息不能仅通过对象所在的内存区域来确定,而必须以某种方式编码在对象头或侧表中。对象头的最低两位用于分别存储标记位(在标记阶段扫描对象时设置)和代际收集的年龄位。
代际收集是通过粘性位实现的:只有当对象的标记位未设置时,才会将对象推送到标记栈中,因此被追踪。当对象达到最老代时,在所谓的“快速清扫”过程中,其标记位不会被重置,这导致这些对象在随后的标记阶段未被追踪。然而,“完全清扫”会导致所有对象的标记位被重置,从而在随后的标记阶段追踪所有对象。对象在每个存活的清扫阶段被提升到下一代。在变异器一侧,通过写入屏障拦截字段写入,如果对象在最后一代,并且正在写入的字段的对象不是,则将对象的地址推送到每个线程的记忆集合中。然后,在标记阶段对这个记忆集合中的对象进行追踪。
Sweeping
对于Julia的对象池的清理可以分为两类:如果池分配器管理的某个页面至少包含一个活动对象,则必须在其死对象中穿插一个空闲列表;如果某个页面根本不包含活动对象,则其底层物理内存可以通过例如在Linux上使用madvise系统调用返回给操作系统。
第一类清扫通过工作窃取进行并行化。对于第二类清扫,如果通过标志 --gcthreads=X,1 启用并发页面清扫,我们将在后台清扫线程中执行 madvise 系统调用,与变异线程并发进行。在收集器的停止世界阶段,最初将包含无活动对象的池分配页面推入 pool_page_lazily_freed。然后,后台清扫线程被唤醒,负责从 pool_page_lazily_freed 中移除页面,对其调用 madvise,并将其插入 pool_page_freed。如上所述,pool_page_lazily_freed 也与变异线程共享。这意味着在分配密集型的多线程工作负载中,变异线程通常会通过直接从 pool_page_lazily_freed 中分配页面来避免分配时的页面错误(来自访问新 mmap 的页面或访问已 madvise 的页面),而后台清扫线程需要对减少数量的页面进行 madvise,因为其中一些页面已经被变异线程占用。
Heuristics
GC启发式通过改变垃圾回收之间的分配间隔大小来调整GC。
GC 启发式算法测量垃圾回收后堆的大小,并根据 https://dl.acm.org/doi/10.1145/3563323 中描述的算法设置下一个回收。总的来说,它认为堆的目标应该与存活堆有平方根关系,并且还应该根据 GC 释放对象的速度和变异器分配的速度进行缩放。启发式算法通过计算正在使用的页面数量和使用 malloc 的对象来测量堆的大小。之前我们通过计算存活对象来测量堆的大小,但这并没有考虑到碎片化,这可能导致错误的决策,这也意味着我们使用线程局部信息(分配)来做出关于进程范围的决策(何时进行垃圾回收),而测量页面意味着决策是全局的。
当堆大小达到最大允许大小的80%时,GC将进行完整的收集。