Inference
How inference works
在Julia编译器中,“类型推断”是指从输入值的类型推导后续值的类型的过程。Julia的推断方法在以下博客文章中进行了描述:
- Shows a simplified implementation of the data-flow analysis algorithm, that Julia's type inference routine is based on.
- Gives a high level view of inference with a focus on its inter-procedural convergence guarantee.
- Explains a refinement on the algorithm introduced in 2.
Debugging compiler.jl
您可以启动一个 Julia 会话,编辑 compiler/*.jl(例如插入 print 语句),然后通过导航到 base 并执行 include("compiler/compiler.jl") 来替换您正在运行的会话中的 Core.Compiler。这个技巧通常比每次更改都重建 Julia 更能加快开发速度。
另外,您可以使用 Revise.jl 包,通过在 Julia 会话开始时使用命令 Revise.track(Core.Compiler) 来跟踪编译器的更改。如 Revise documentation 中所述,对编译器的修改将在保存修改后的文件时反映出来。
一个方便的推断入口是 typeinf_code。以下是对 convert(Int, UInt(1)) 进行推断的演示:
# Get the method
atypes = Tuple{Type{Int}, UInt} # argument types
mths = methods(convert, atypes) # worth checking that there is only one
m = first(mths)
# Create variables needed to call `typeinf_code`
interp = Core.Compiler.NativeInterpreter()
sparams = Core.svec() # this particular method doesn't have type-parameters
run_optimizer = true # run all inference optimizations
types = Tuple{typeof(convert), atypes.parameters...} # Tuple{typeof(convert), Type{Int}, UInt}
Core.Compiler.typeinf_code(interp, m, types, sparams, run_optimizer)如果您的调试冒险需要 MethodInstance,您可以通过调用 Core.Compiler.specialize_method 使用上述许多变量来查找它。可以通过以下方式获得 CodeInfo 对象:
# Returns the CodeInfo object for `convert(Int, ::UInt)`:
ci = (@code_typed convert(Int, UInt(1)))[1]The inlining algorithm (inline_worthy)
大部分最困难的内联工作在 ssa_inlining_pass! 中进行。然而,如果你的问题是“为什么我的函数没有内联?”那么你最有可能对 inline_worthy 感兴趣,它决定是否内联函数调用。
inline_worthy implements a cost-model, where "cheap" functions get inlined; more specifically, we inline functions if their anticipated run-time is not large compared to the time it would take to issue a call to them if they were not inlined. The cost-model is extremely simple and ignores many important details: for example, all for loops are analyzed as if they will be executed once, and the cost of an if...else...end includes the summed cost of all branches. It's also worth acknowledging that we currently lack a suite of functions suitable for testing how well the cost model predicts the actual run-time cost, although BaseBenchmarks provides a great deal of indirect information about the successes and failures of any modification to the inlining algorithm.
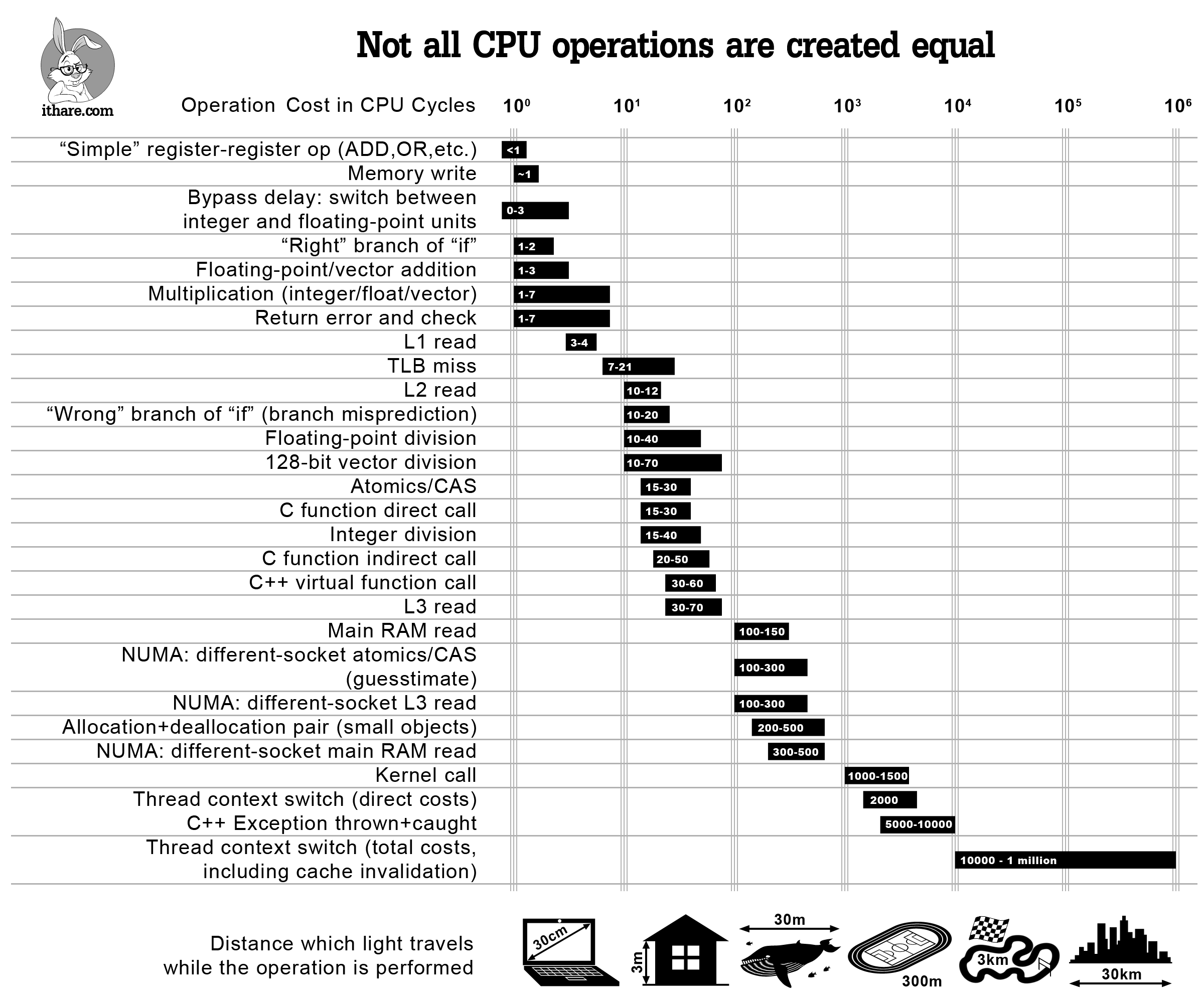
成本模型的基础是一个查找表,实现在 add_tfunc 及其调用者中,该表为每个 Julia 的内置函数分配一个估计成本(以 CPU 周期为单位)。这些成本基于 standard ranges for common architectures(有关更多详细信息,请参见 Agner Fog's analysis)。
{kind=link}
我们用一些特殊情况来补充这个低级查找表。例如,一个 :invoke 表达式(所有输入和输出类型都已提前推断的调用)被分配一个固定的成本(目前为 20 个周期)。相比之下,一个 :call 表达式,对于除内置函数/内置方法以外的函数,表示该调用将需要动态调度,在这种情况下,我们分配一个由 Params.inline_nonleaf_penalty 设置的成本(目前设置为 1000)。请注意,这不是动态调度原始成本的“第一原理”估计,而仅仅是一个启发式指标,表明动态调度是极其昂贵的。
每个语句的总成本在一个名为 statement_cost 的函数中进行分析。您可以按如下方式显示与每个语句相关的成本:
julia> Base.print_statement_costs(stdout, map, (typeof(sqrt), Tuple{Int},)) # map(sqrt, (2,))
map(f, t::Tuple{Any}) @ Base tuple.jl:281
0 1 ─ %1 = $(Expr(:boundscheck, true))::Bool
0 │ %2 = Base.getfield(_3, 1, %1)::Int64
1 │ %3 = Base.sitofp(Float64, %2)::Float64
0 │ %4 = Base.lt_float(%3, 0.0)::Bool
0 └── goto #3 if not %4
0 2 ─ invoke Base.Math.throw_complex_domainerror(:sqrt::Symbol, %3::Float64)::Union{}
0 └── unreachable
20 3 ─ %8 = Base.Math.sqrt_llvm(%3)::Float64
0 └── goto #4
0 4 ─ goto #5
0 5 ─ %11 = Core.tuple(%8)::Tuple{Float64}
0 └── return %11
行成本在左侧列中。这包括内联和其他形式优化的后果。